
Digital engineering is an approach to understanding and managing modern engineered systems that reflects how they are built and operated today. As systems become more software-driven,...
Continue Reading
Digital engineering is an approach to understanding and managing modern engineered systems that reflects how they are built and operated today. As systems become more software-driven,...
Continue Reading
Digital twin applications create the most value when they do more than simulate or visualize a system. In complex operational environments, they must help maintain the current system state,...
Continue Reading
CAD data integration in digital engineering is the process of connecting CAD-derived geometry and metadata to a system representation that preserves meaning, relationships, and intent...
Continue Reading
Digital twin creation has moved beyond static models or visual replicas of physical assets. In enterprise environments, it refers to establishing a continuously executing system abstraction...
Continue Reading
Digital twins in manufacturing refer to continuously executing orchestration platforms within manufacturing environments that enable real-time coordination, system-level reasoning, and...
Continue ReadingWhat Is Digital Transformation in Engineering? Digital transformation in engineering is the shift from fragmented, tool-centric workflows to connected, system-level environments where data,...
Continue Reading
Digital twins promise real-time awareness, predictive insight, and closed-loop control, but none of these outcomes are possible without a continuous stream of accurate, well-structured, and...
Continue Reading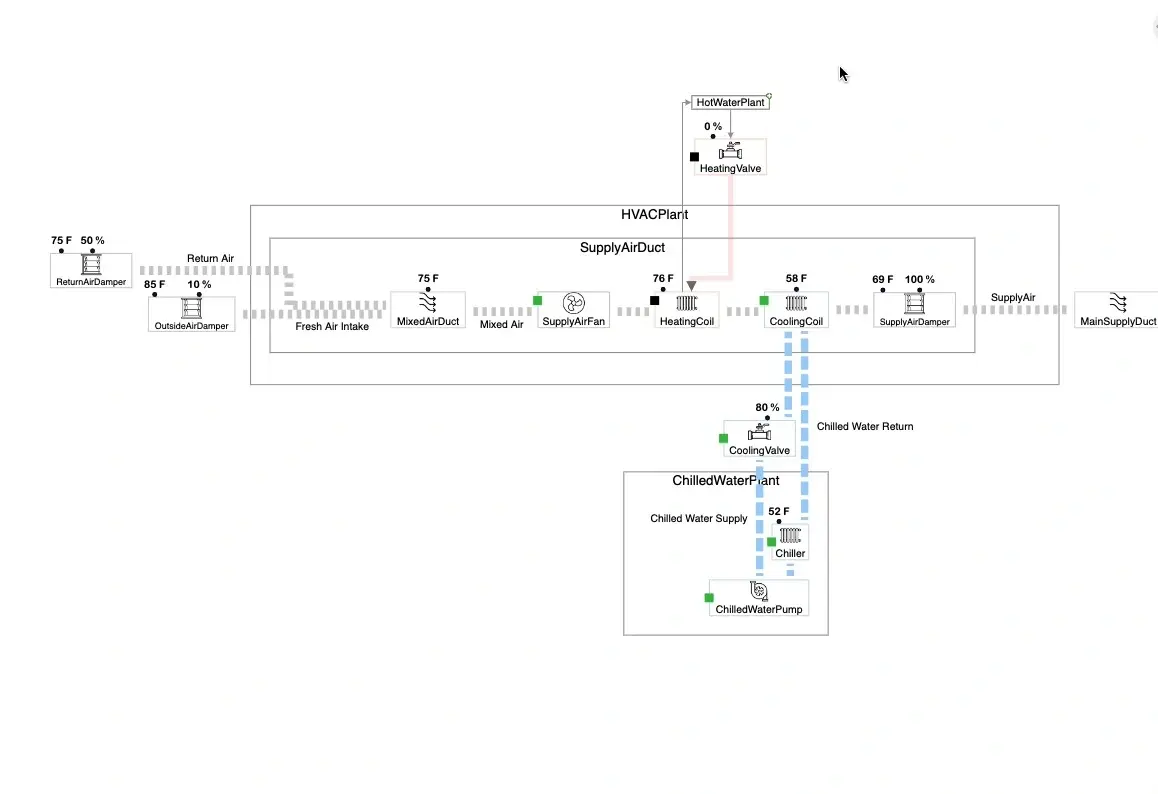
Digital twin technology is rapidly becoming a foundational layer in enterprise systems engineering. As organizations move toward more interconnected, software-defined, and data-driven...
Continue Reading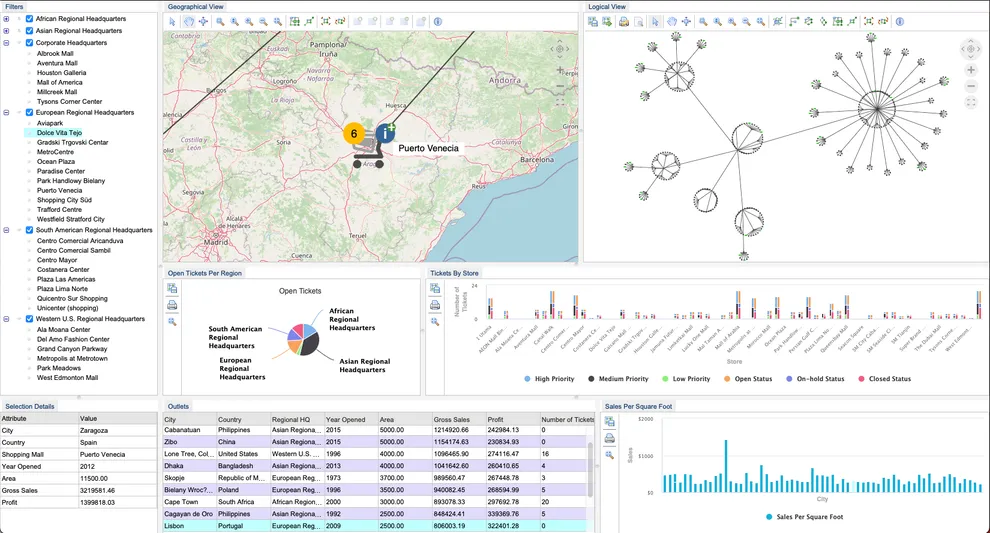
Understanding the distinctions between structured data systems, such as databases, knowledge bases, and knowledge graphs, is essential for anyone working with information in engineering,...
Continue Reading
Submit a Comment