
Liana Kiff
Exploring the Revolution: Graph Databases in Modern Data Management
Graph databases and other graph-based approaches to data management represent a paradigm shift in database technology, fundamentally changing how data relationships are stored and queried. Unlike traditional relational databases that store data in rows and tables, graph databases are designed around the concept of nodes and edges. This architecture allows for the representation of data in a way that mirrors the complexity and interconnectedness of real-world systems. Whether it's social networks, recommendation engines, or fraud detection systems, the ability to map intricate relationships between data points makes graph databases an essential tool in modern data architecture.
A critical decision point for organizations looking to leverage the full potential of their data through either graph databases or knowledge graphs is to determine how to approach their own "knowledge graph vs graph databases" discussion to arrive at the right choice for their short-term and long-term business goals.
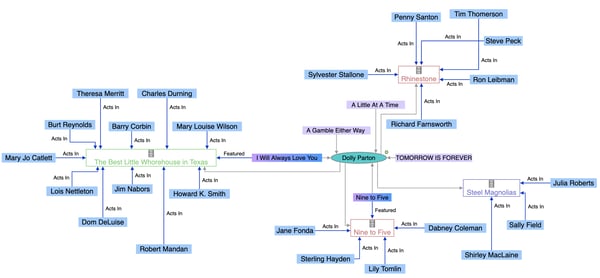
An example knowledge graph showing the relationships between movies, songs, artists and actors.
What makes Knowledge Graphs different than Graph Databases?
As the names might imply, the differences between these two approaches lie in their fundamental origins. Both approaches deliver powerful tools to organize, store, and analyze connected data (nodes and edges). The flexibility of both of these graph-based solutions supports agile development and evolving data schemas without the need for extensive database redesign. This adaptability is crucial for applications that must evolve rapidly to meet changing requirements or incorporate new types of data.
Knowledge Graphs are founded on the principles of describing data as knowledge. They are semantically rich, which makes them more verbose—that is, more meta-data is required to describe the same facts. However, they are based on strong standards for this level of descriptive detail that support advanced analytics and AI, in the form of inferencing: expanding knowledge organically through the application of logic. Knowledge graphs natively support the distribution of knowledge across the internet in a form that can be shared unambiguously through the use of standard definitions, called ontologies. Knowledge Graphs focus on the precise description of knowledge over the optimization of how to store that knowledge. Knowledge Graphs are typically described by a format called a "triple," and these triples are managed in a database called a "triple store."
On the other hand, property graph databases were born out of a need for speed in storing, processing, and analyzing connected data, such as social networks. They are designed to optimize processing, performance, and the ease of communication and programming to deliver answers to questions quickly. In other words, property graph databases were designed for speed of software development, with less emphasis on the standardization and interoperability of the knowledge they contain, or validation of that knowledge through logic. There are many competing graph database solutions that do not follow the same standards, and the information that these graphs contain is usually very specific to the business or the problem being solved.
The core advantage of graph databases lies in their efficiency and speed in handling connected data, stemming from their ability to store relationships between entities directly. This means that operations like traversing connections or exploring networks are inherently faster and more intuitive than relational models, and may perform better than triple stores for common problems.
The core advantage of a Knowledge Graph is in supporting interoperability, and inference, through the strong standards that are managed by the W3C consortium. Knowledge graphs provide tools to identify when the data they contain doesn't make sense, and the standards support combining information from many unrelated sources into a larger knowledge graph that still makes sense.
If your business is to build applications where relationships between data are key to delivering insights and functionality, and the discussion about Knowledge Graph vs Graph Database comes up, the choice does not have to be either/or. These tools do very different things, and they can be employed together to get the best impact from both of them in your graph data strategy.
By providing a more natural way to model and query relationships, graph databases not only enhance the development of applications but also open up new possibilities for understanding and leveraging data in innovative ways. The decision between utilizing Knowledge Graph vs Graph Databases thus centers on assessing which approach takes priority, given the evolving needs of an organization, considering both the immediate benefits and the long-term scalability of the data architecture chosen.
The rise of graph databases reflects a broader trend toward specialized database systems designed to address specific challenges in data management. As the volume, variety, and velocity of data continue to grow, the limitations of traditional database models become increasingly apparent. Graph databases, with their focus on relationships, offer a powerful solution to these challenges, enabling more dynamic, responsive, and effective data-driven applications and insights. Knowledge Graphs provide a way to bring some order into the description of the knowledge in the graph, so that speed and flexibility don't leave you with an ungoverned graph that might provide the wrong answers.
The Knowledge Graph vs Graph Databases debate underscores the importance of selecting good data management strategies to harness the full potential of data in driving organizational success.
What is a Graph Database?
A graph database is a type of database that utilizes graph structures for semantic queries, with nodes, edges, and properties to represent and store data. The key concept behind a graph database is the graph, which directly associates entities (nodes) and the relationships (edges) that connect them. Each node represents an entity (such as a person, place, or thing), and each edge represents a connection or relationship between two nodes. This structure allows for a highly flexible and intuitive representation of complex networks of relationships, like social networks, organizational structures, or communication networks. Graph databases offer a significant performance boost in these scenarios, providing a compelling argument for their adoption over traditional models or even within the context of knowledge graphs.
Graph databases excel in scenarios where relationships between data points are as important as the data points themselves. They enable efficient querying and traversing of relationships, making them particularly useful for applications like social media analytics, recommendation systems, and fraud detection, where understanding the connections between entities can provide significant insights and advantages.
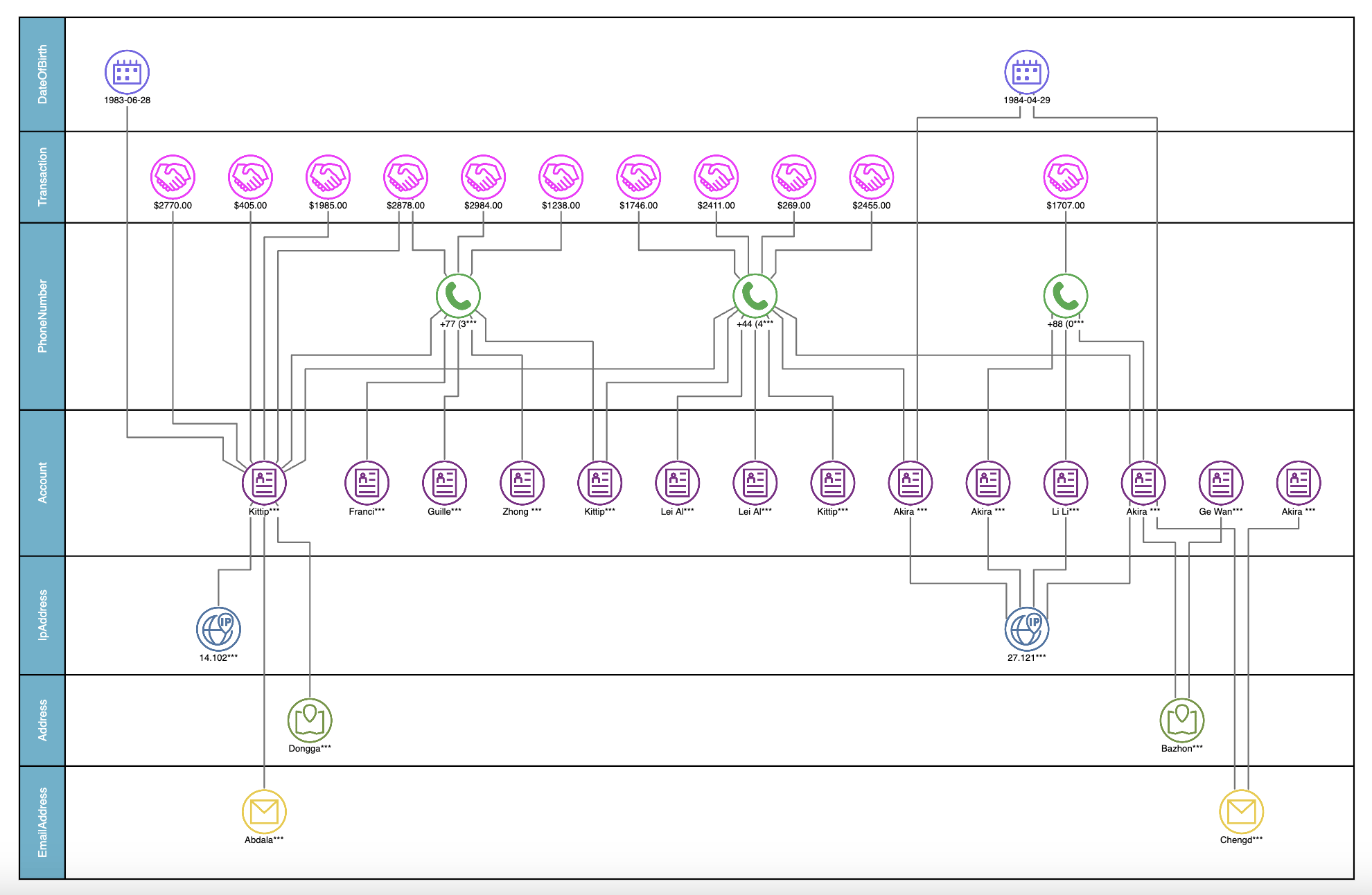
A graph showing the relationships between transactions, accounts, addresses and more in a fraud investigation.
Unlike relational databases, which require join operations to query relationships between tables, graph databases treat relationships as first-class citizens. This approach not only simplifies data modeling and querying but also improves performance for operations that involve traversing complex networks of relationships. The ability to dynamically add nodes, edges, and properties without restructuring the entire database schema offers flexibility and scalability, making graph databases well-suited for agile development environments and applications with evolving data models.
Graph databases use specialized query languages, such as Cypher for Neo4j or Gremlin for Apache TinkerPop-enabled databases, which are designed to query and manipulate the graph structure efficiently. These languages allow developers to express complex hierarchical and network-based queries in a concise and readable format, enabling sophisticated data analysis and manipulation directly aligned with the graph model.
Key Features of Graph Databases
Graph databases excel in areas where relational databases struggle, primarily due to their inherent design focused on relationships and connectivity, which is a critical consideration in the Knowledge Graph vs Graph Databases decision-making process. The key features of graph databases include:
- Performance: Graph databases are optimized for querying complex, connected data. They can quickly traverse networks of relationships, enabling efficient execution of deep relational queries without the need for extensive joins that can slow down relational databases.
- Flexibility: Unlike relational databases that require a predefined schema, graph databases are schema-less. This flexibility allows for easy modifications and additions to the database structure as application requirements evolve.
- Intuitive Data Modeling: The graph model is highly intuitive, closely mirroring real-world relationships. This makes it easier for developers and data analysts to model and understand complex scenarios, enhancing the development process and data analysis.
- Advanced Analytics: With their ability to efficiently manage connected data, graph databases support advanced analytics and algorithms, including pathfinding, pattern matching, and social network analysis. This capability is essential for applications that rely on understanding the depth and strength of relationships.
- Scalability: Graph databases are designed to scale horizontally, accommodating growth in data volume and complexity without compromising performance. This scalability is critical for applications with expanding datasets and user bases.
These features make graph databases a preferred choice for applications that require efficient handling of connected, complex datasets, providing significant advantages over traditional database models in terms of performance, flexibility, and analytical capabilities.
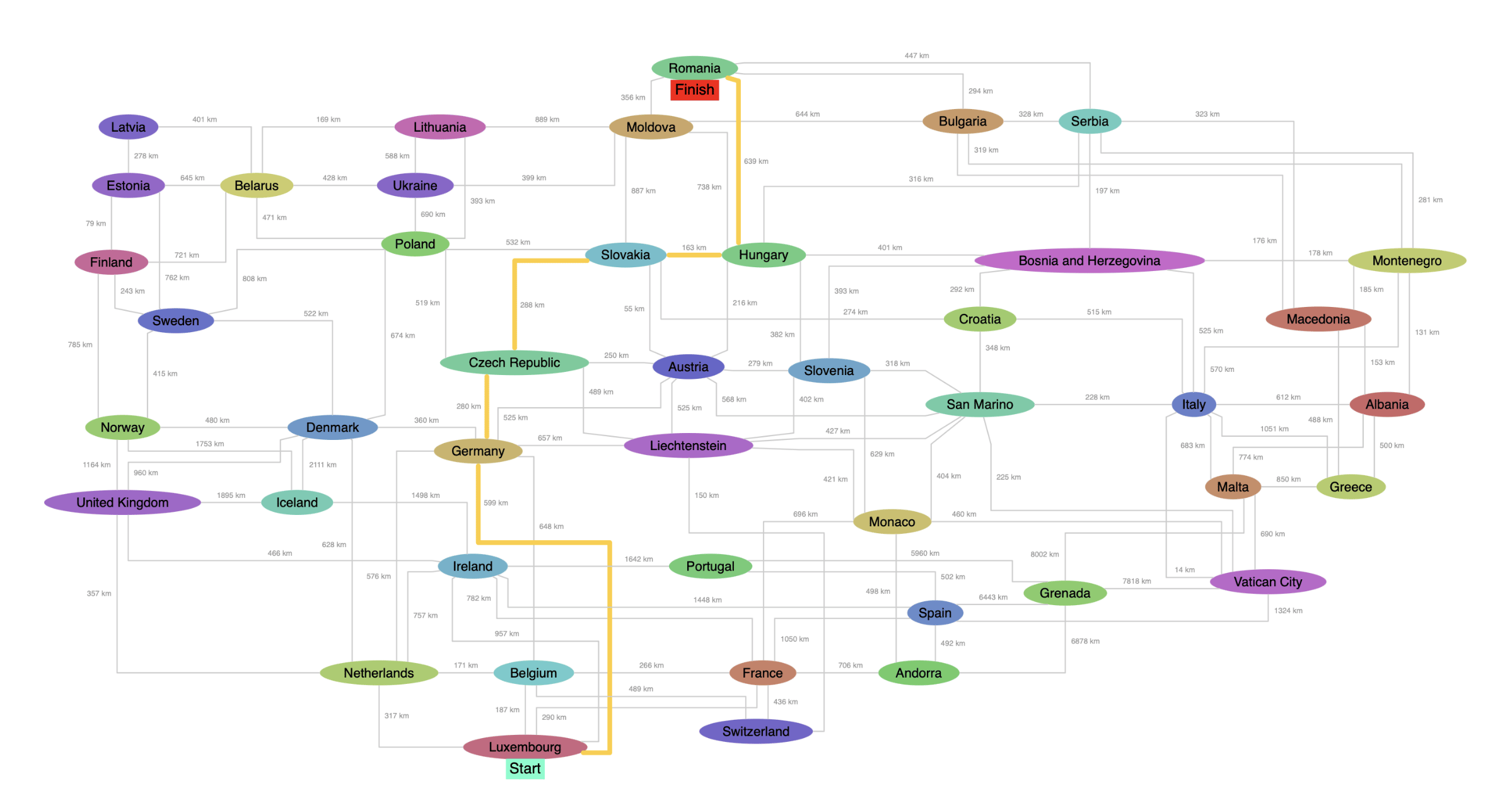
A graph of countries and mileage between them showing the shortest path between two countries.
Overview of Graph Database Technologies and Platforms
The landscape of graph database technologies and platforms is diverse, with several leading solutions catering to different needs and scales of applications. Key players in the graph database market include Neo4j, Amazon Neptune, and Microsoft Azure Cosmos DB, among others. Each platform offers unique features and capabilities, but all are designed to optimize the storage, management, and querying of connected data.



Neo4j
Neo4j is one of the most popular graph database platforms, renowned for its high performance and comprehensive set of features. It supports a rich query language called Cypher, which is specifically designed for graph databases, making it easier to model and query complex relationships.
Amazon Neptune
Amazon Neptune is a fully managed graph database service offered by AWS (Amazon Web Services). It provides a robust and scalable solution for building graph applications. Neptune supports both property graphs and RDF graphs, making it versatile for various use cases. Its managed nature simplifies database administration tasks.
Microsoft Azure Cosmos DB
Microsoft Azure Cosmos DB offers multi-model database capabilities, including support for graph data models. It provides global distribution, high availability, and low-latency access to data. With its Gremlin query language support, it enables users to work with graph data efficiently. Cosmos DB is suitable for large-scale and globally distributed applications.
Other Platforms
In addition to the mentioned platforms, there are other notable graph database solutions like OrientDB, ArangoDB, and JanusGraph, each with its own strengths and use cases. Organizations should assess their specific requirements, scalability needs, and cloud preferences when choosing a graph database platform.
The diverse range of graph database technologies empowers organizations to select the platform that aligns best with their data management and analysis needs. Whether it's the high performance of Neo4j, the managed convenience of Amazon Neptune, or the global reach of Azure Cosmos DB, these platforms play a crucial role in harnessing the power of connected data.
Key Aspects of Knowledge Graph and Graph Databases
Understanding the key aspects of knowledge graphs and graph databases is essential for grasping their respective strengths and applications, especially when comparing Knowledge graph vs Graph Databases to determine the best fit for specific scenarios.
Data Modeling
Data modeling is a fundamental aspect of both knowledge graphs and graph databases, albeit with nuanced differences.
Vertices and Edges in Graph Databases
In graph databases, data modeling revolves around the concept of nodes (vertices) and relationships (edges). Vertices represent entities, while edges denote the connections or relationships between these entities. This structure is highly efficient for modeling and querying interconnected data, making it ideal for use cases that demand rapid traversal of relationships. Graph databases prioritize the operational aspects of data management, allowing for dynamic schema-less modeling, where data structures evolve with changing requirements.
Entities and Relationships in Knowledge Graphs
Knowledge graphs extend the data modeling concept by incorporating semantic enrichment. In knowledge graphs, entities represent concepts or real-world objects, and relationships between entities carry a richer semantic context. Ontologies define the types of entities and relationships, adding layers of meaning to the data. This semantic layer enables knowledge graphs to not only represent data but also understand it, facilitating inference and reasoning. Knowledge graphs excel in applications that require a deep comprehension of data, such as AI, machine learning, and complex decision-making processes.
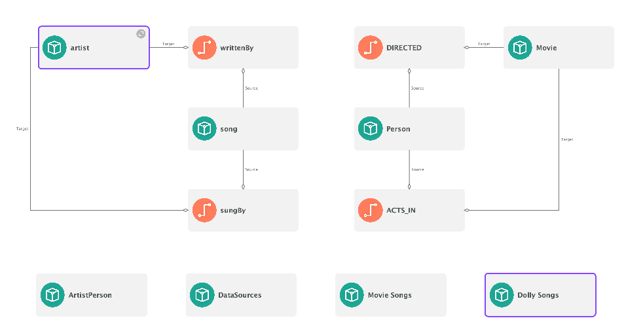
A knowledge graph schema example.
Query Languages and Tools
Query languages play a pivotal role in interacting with both knowledge graphs and graph databases, underlining the distinctions and considerations central to the Knowledge Graphs vs Graph Database discourse. Depending on the technology, different query languages and tools are employed to extract information and insights from these data structures.
Cypher and Gremlin for Graph Databases
Cypher
Specifically designed for graph databases, Cypher is notable for its human-readable syntax, making it accessible to both developers and data analysts. It focuses on pattern matching, enabling users to frame their queries in terms of patterns of nodes (vertices) and relationships (edges), aligning with the graph's natural data representation. This compatibility makes Cypher an intuitive choice for those working within the graph database realm, emphasizing operational efficiency and ease of use.
Gremlin
Gremlin offers a versatile, domain-agnostic approach to querying graph databases. It adopts a functional programming style, facilitating complex data traversal, filtering, and manipulation through a sequence of chained operations. Though Gremlin presents a steeper learning curve with its syntactical complexity, it rewards users with the flexibility to articulate sophisticated queries and analyses, showcasing the technical depth available in graph databases.
SPARQL for Knowledge Graphs
Serving as the standard query language for knowledge graphs, especially those structured on the RDF (Resource Description Framework), SPARQL excels in its capacity for semantic querying. It enables expressive interrogation of knowledge graphs, adept at navigating intricate relationships and drawing inferences from the connected data. SPARQL's design for reasoning over linked data, through graph pattern queries, highlights its strength in applications requiring deep data integration and inference, a hallmark of knowledge graph utilization.
The choice between knowledge graphs and graph databases—and by extension, the selection of Cypher, Gremlin, or SPARQL—rests on the specific technological needs and application contexts. Cypher and Gremlin enhance the operational and developmental flexibility of graph databases, while SPARQL's semantic depth and inferential capabilities cater to the complex data comprehension needs of knowledge graphs. This distinction underscores the strategic considerations businesses must navigate when selecting the appropriate data structure and query language for their unique challenges.
Scalability and Performance
Scalability and performance are critical factors when considering knowledge graphs and graph databases. Each technology exhibits distinct characteristics in terms of accommodating data growth and delivering efficient query performance.
Graph databases are engineered for horizontal scalability, making them suitable for handling growing datasets and high query loads. They achieve scalability through techniques like sharding, replication, and distributed architectures. This allows organizations to expand their graph databases to meet increasing demands without sacrificing performance. Graph databases excel in query performance, especially for use cases that involve traversing relationships. They are optimized for real-time querying of complex, highly interconnected data. By maintaining indexes on nodes and relationships, graph databases deliver sub-second query responses even as the dataset size increases.
Knowledge graphs, while capable of accommodating extensive knowledge bases, may face challenges in terms of scalability, especially in scenarios where the graph becomes exceedingly large. Scaling knowledge graphs often involves careful management of ontologies, data partitioning, and distributed knowledge graph architectures. This aspect is crucial in considering Knowledge Graphs vs Graph Database development and management, particularly when considering the infrastructure and methodologies required to support scalability.
Performance considerations for knowledge graphs revolve around inferencing and semantic enrichment. Complex reasoning tasks, such as ontology-based inferencing, can impact query response times. While knowledge graphs may not match the sub-second performance of graph databases for relationship traversals, they excel in tasks that require semantic understanding, reasoning, and advanced analytics.
Choosing whether to use knowledge graphs and graph databases, alone or in concert, depends on the specific use case. Graph databases are ideal for applications demanding real-time, highly performant querying of interconnected data. Knowledge graphs shine when the emphasis is on deep comprehension, semantic reasoning, and advanced analytical capabilities, even if it means slightly longer query times. However, the inferences generated by a semantic knowledge graph can be exported and stored in a graph database, where programmers have the tools they require for speed.
This nuanced evaluation is essential in the "Knowledge Graph vs Graph Database" consideration, guiding organizations toward the most appropriate technologies for their data management and analysis needs. Graph databases deliver scalability and performance in data processing. Knowledge graphs deliver scalability and performance in organizing and harnessing knowledge for consistency, comprehension and validation.
Types of Data Covered - Structured and Unstructured Data
Understanding the types of data that both knowledge graphs and graph databases can accommodate is essential for selecting the appropriate technology to manage and analyze your data.
Graph databases are versatile when it comes to handling structured and semi-structured data. They excel in managing highly interconnected data, making them suitable for scenarios where relationships between data points play a vital role. Structured data, such as customer profiles, can be effectively modeled in graph databases, enabling efficient querying and analysis.
While graph databases primarily focus on structured data, they can also incorporate unstructured or semi-structured data to some extent. However, managing large volumes of unstructured text or media files may not be their primary strength.
Knowledge graphs are well-suited for integrating and managing structured, semi-structured, and unstructured data. They offer a semantic layer that allows data to be enriched with context and meaning. This capability makes them an excellent choice for scenarios where diverse data types, including text, images, and multimedia content, need to be interconnected and analyzed in a contextual manner.
Knowledge graphs use ontologies to define the structure of data and relationships, enabling seamless integration of various data formats. This flexibility and semantic enrichment empower organizations to create comprehensive representations of their data landscapes, incorporating both structured and unstructured information.
What is a Knowledge Graph?
A knowledge graph differs from a property graph database in its basic structure. Knowledge graphs have nodes (subjects and objects), and edges (predicates). In a graph database, either nodes or edges can have properties. In a knowledge graph, all properties are linked by another edge to the thing they describe. This is one of the features of knowledge graphs that support very precise definition of each aspect of the knowledge they embody. Knowledge graphs use ontologies to support semantic enrichment on the knowledge they hold.
Ontologies
Knowledge graphs heavily rely on ontologies, which are formal representations of knowledge domains. Ontologies define the entities, relationships, and axioms that govern the semantics of data in a knowledge graph. They provide a structured framework for organizing data, allowing organizations to capture domain-specific knowledge effectively.
There are many ontologies developed by authorities in their own domains, which can be readily applied to standardize the description of data for your application. You may be the authority who needs to create an ontology for your own domain of expertise, or, you might use one or more ontologies developed by someone else to help you map proprietary terminology to concepts that are more standard within your industry. Ontologies can be combined in powerful ways to grow the information you gather about the "things" your data describes, without having to redefine everything you already know to make things fit. Because ontologies are standardized, some of the queries and applications people create to extract data from them are also portable.
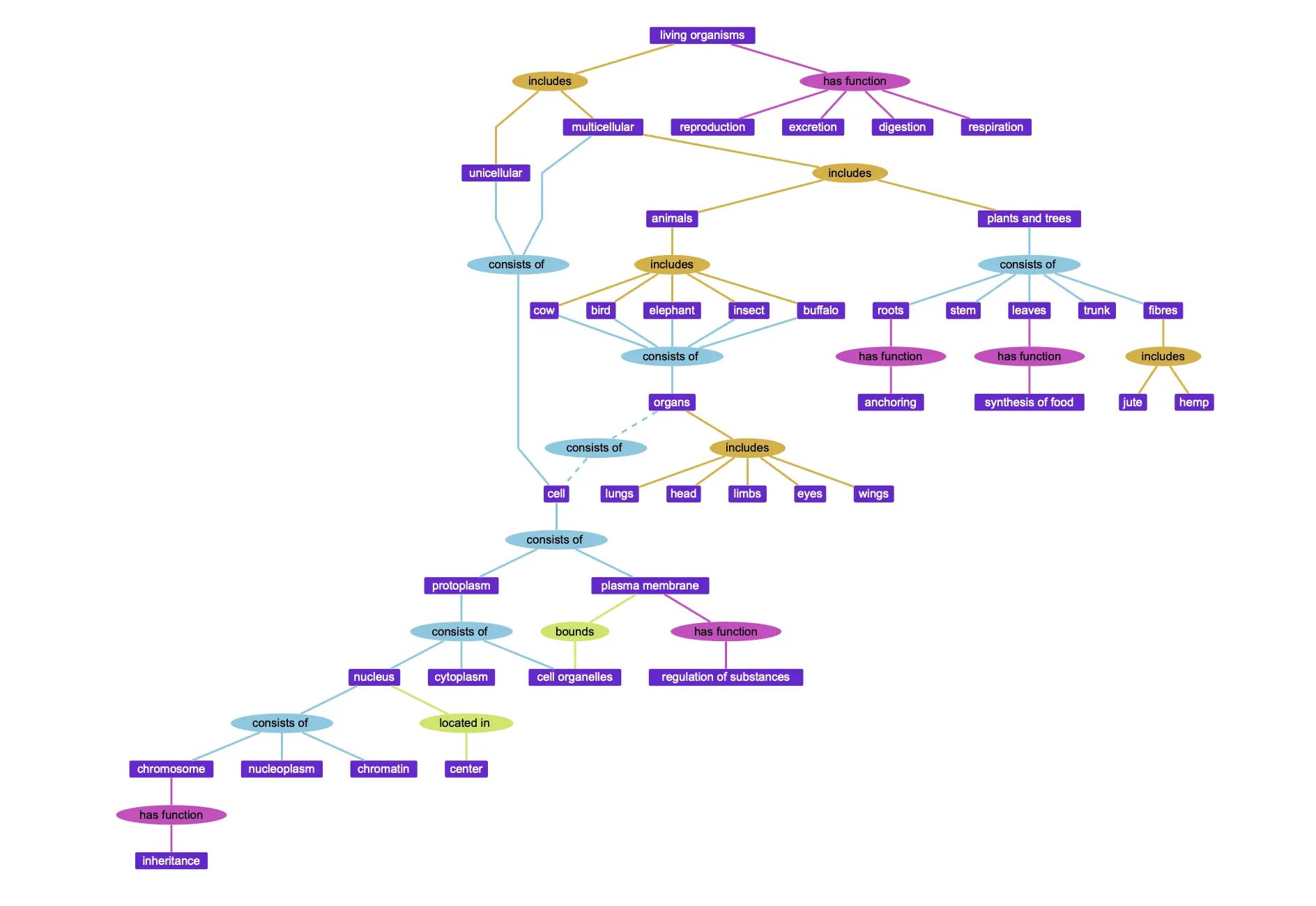
Example ontology for living organisms.
Semantic Enrichment
Semantic enrichment is a core feature of knowledge graphs. It involves adding semantic metadata to data elements enriching them with contextual information. This process enhances the understanding of data and enables advanced analytics and reasoning. Semantic enrichment in knowledge graphs facilitates tasks such as concept disambiguation, inference, and contextual search.
Real-Time Data Integration
Both knowledge graphs and graph databases can support real-time data integration, but the approach may differ.
Graph databases are designed for real-time querying and analysis of data. They excel in scenarios where data updates or changes need to be reflected instantly. Real-time data integration in graph databases involves efficient indexing and update mechanisms to ensure that queries always reflect the latest data state.
Knowledge graphs also support real-time data integration but may emphasize semantic enrichment and reasoning over instant updates. In knowledge graphs, real-time integration often involves aligning incoming data with existing ontologies and enriching it semantically. This approach ensures that new data seamlessly integrates with the existing knowledge base, enabling advanced analytics and inference.
The decision to use knowledge graphs, graph databases, or both in concert hinges on an organization's unique data requirements and objectives. Knowledge graphs excel in semantic enrichment and contextual analysis across varied data formats, leveraging ontologies for deep, meaningful insights. Conversely, graph databases focus on the efficient querying of highly interconnected data, offering rapid access and analysis capabilities for complex relational networks. This distinction is crucial for organizations aiming to optimize their data management strategy to align with specific operational needs and analytical goals.
Navigating the Crossroads: Choosing Knowledge Graphs or Graph Databases for Your Project
The decision to use a graph database or a knowledge graph ultimately hinges on your project's specific goals and data characteristics. It's essential to conduct a thorough analysis of your project needs and consider the following factors:
- Data Complexity: Assess the variety and complexity of your data. If it includes structured, semi-structured, and unstructured components, a knowledge graph may be more suitable to manage and harness the value in that data.
- Query Performance: Evaluate whether real-time query performance is a critical requirement. If so, a graph database may be the better choice for storing and delivering data at the application layer.
- Semantic Understanding: Consider whether your project benefits from semantic enrichment, inferencing, and advanced analytics. Knowledge graphs excel in this regard.
- Use Case: Align the technology choice with your project's primary use case scenarios. Both knowledge graphs and graph databases have their strengths in specific applications, and can be effectively used in concert.
By carefully weighing these considerations, you can make an informed decision that aligns with your project's objectives and ensures optimal data management and analysis.
The question of "Knowledge Graph vs Graph Database," extends beyond technical specifications to encompass strategic alignment with your project's long-term vision and operational dynamics. This decision is not merely about selecting a data management solution—it's about choosing a foundation that will support your project's or your organization's evolution, scalability, and future-proofing needs. Graph databases, with their emphasis on real-time query performance and efficient handling of highly interconnected data, offer a robust solution for projects that require agile data interaction and rapid insights from complex relationships. On the other hand, knowledge graphs, with their deep semantic understanding and inferencing capabilities, are unparalleled in projects where the depth of data comprehension and the ability to draw nuanced conclusions from vast, diverse datasets are paramount.
Thus, when deliberating "Knowledge Graphs vs Graph Databases," it's crucial to envision how each option will integrate with your project's lifecycle, from initial development through scaling and potential pivots in focus or functionality. This forward-looking approach ensures that the chosen technology not only meets current project requirements but also accommodates future demands, fostering innovation and sustaining value over time. By integrating these considerations into your decision-making process, you align your project with a data management framework that truly resonates with your objectives, ensuring a strategic fit that leverages the unique advantages of graph databases and knowledge graphs to their fullest potential.
About the Author
Liana Kiff is a Senior Consultant, bringing more than 25 years of software innovation, design, and development experience to Tom Sawyer Software. Prior to Tom Sawyer Software, Liana worked on innovative graph-based approaches to industrial information management at Honeywell’s corporate labs, where she acquired deep domain knowledge related to commercial, and industrial customers of advanced control solutions. As a champion of information standards and model-driven approaches, she led the development of a common ontology for use across a wide range of building automation solutions and managed the development of cloud-based services and APIs for enterprise software development. Liana holds a Master of Software Engineering degree from the University of Minnesota.
FAQ
Are knowledge graphs and graph databases the same thing?
No, knowledge graphs and graph databases are not the same. A graph database primarily focuses on efficiently storing and querying data relationships, while a knowledge graph goes beyond that by adding semantic context and meaning to the data through ontologies. This semantic layer enables reasoning and inference, making knowledge graphs more suitable for AI and machine learning applications.
Can I convert a graph database into a knowledge graph?
Yes, you can convert a graph database into a knowledge graph by adding ontologies and a semantic layer to your existing data. This involves explicitly defining the relationships between entities and incorporating rules for reasoning and inference. By doing this, you allow your system to not only store data relationships but also to understand and infer new relationships based on the data.
How do knowledge graphs handle updates to ontologies?
In knowledge graphs, updating ontologies can be more complex than in a graph database, as the ontologies are foundational to the structure and reasoning capabilities. Changes to the ontology may require realigning data to the new schema and ensuring that all relationships are still valid. However, many tools supporting knowledge graphs provide features for updating ontologies without extensive downtime or data migration.
Do knowledge graphs require a specific type of storage technology?
Knowledge graphs often rely on RDF (Resource Description Framework) and require specialized graph databases or triple stores for storage. However, some modern platforms support a hybrid model where both graph databases (for relationship querying) and knowledge graphs (for semantic reasoning) can be implemented on the same infrastructure.
Can I use graph algorithms with knowledge graphs and graph databases?
Yes, you can use graph algorithms with both knowledge graphs and graph databases. In graph databases, algorithms such as shortest path, centrality, and clustering are commonly used to analyze node relationships. Knowledge graphs can also use these algorithms, but they often extend their functionality by applying inference and reasoning based on the semantic relationships defined in their ontology. This enables deeper insights beyond just the structural properties of the graph.
Submit a Comment