
Alejandro Fabián Silva Grifé
In the rapidly evolving digital landscape, the ability to organize, understand, and extract meaningful insights from vast amounts of data is paramount. AWS knowledge graphs emerge as a pivotal solution, harnessing the power of AWS Neptune to create intricate, scalable, and intelligent networks of data relationships. This article delves into the transformative potential of AWS for crafting sophisticated knowledge graphs, setting the stage for a deep dive into the technology that is reshaping how businesses and developers approach data complexity and connectivity.
The integration of AWS Neptune, a fast, reliable, fully managed graph database service, offers a seamless pathway to constructing knowledge graphs that can handle the dynamic nature of today's data demands. By enabling efficient storage, management, and retrieval of data relationships, AWS knowledge graphs empower users to unlock a deeper understanding of data sets, driving innovation and strategic decision-making across various industries.
Embarking on this journey requires a blend of technical acumen, strategic foresight, and a clear understanding of the objectives behind creating a knowledge graph. Whether it's enhancing customer experiences, streamlining operations, or uncovering new insights, the goal is to leverage AWS's capabilities to forge knowledge graphs that are not only intelligent but also aligned with the unique needs and challenges of your domain.
As we proceed, this article will guide you through the foundational concepts, implementation strategies, and optimization techniques essential for building effective and impactful knowledge graphs with AWS. From beginners curious about the basics to seasoned professionals seeking advanced tactics, this exploration offers valuable insights into the world of AWS knowledge graphs.
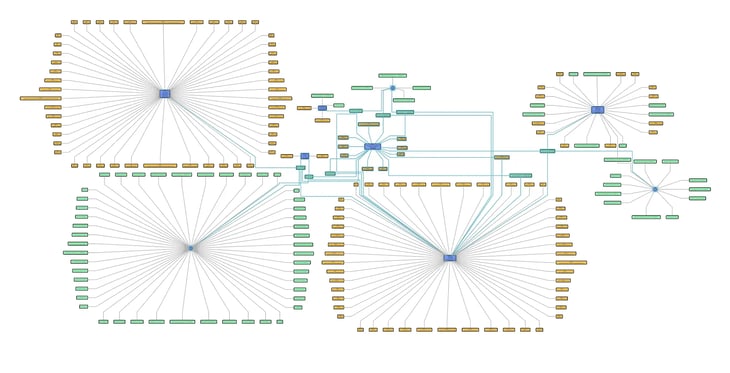
A knowledge graph with advanced visualization.
The Foundation of Knowledge Graphs in AWS
Before diving into the intricacies of building a knowledge graph with AWS, it's crucial to grasp the fundamental principles of knowledge graphs and how AWS Neptune serves as the cornerstone for these sophisticated data structures. Knowledge graphs represent a revolutionary approach to managing and interpreting data, enabling a semantic understanding of diverse information sources through interconnected data points.
What is a Knowledge Graph?
At its core, a knowledge graph describes the connections between things much like our brains, taking facts and linking them in a meaningful way with related physical or logical concepts. In a knowledge graph, entities like people, places, objects, and concepts, are represented as nodes where each node stands for a unique entity. The connections or relationships between these entities are represented as edges.
AWS Neptune is a graph database that uses a graph-structured data model to store interconnected descriptions of entities—objects, events, or concepts—along with their interrelations. This graph structure facilitates a more nuanced and contextual understanding of data, allowing for intricate queries and analytics that traditional relational databases struggle to support efficiently.
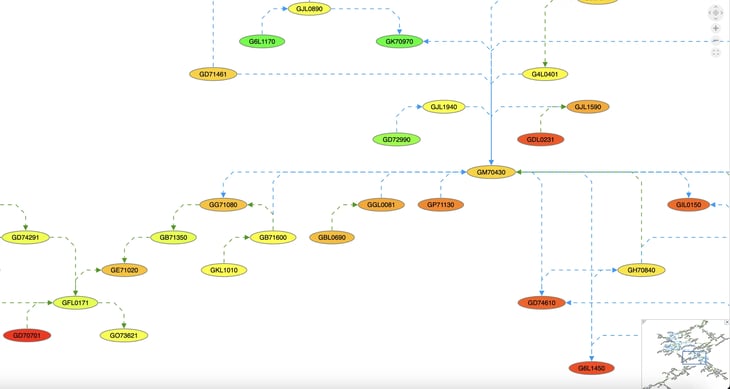
Diagram illustrating the structure of a basic knowledge graph.
AWS Neptune: Powering the Next Generation of Knowledge Graphs
AWS Neptune plays a pivotal role in this ecosystem, offering a fully managed graph database service optimized for storing billions of relationships and querying the graph with milliseconds latency. Neptune supports popular graph models like Property Graph and W3C's RDF, along with their respective query languages, Apache TinkerPop Gremlin and SPARQL, enabling developers to build knowledge graphs that are both versatile and scalable.
Key Features of AWS Neptune:
Highly Scalable
Neptune is designed to scale automatically, accommodating vast amounts of data without compromising performance.
Fully Managed
AWS handles the maintenance, backups, and scalability, allowing developers to focus on application development.
Secure
Neptune integrates with AWS Identity and Access Management (IAM) to provide robust security features, ensuring data integrity and access control.
Why Choose AWS Neptune for Your Knowledge Graph?
Choosing AWS Neptune for your knowledge graph implementation comes down to its ability to handle complex, connected data efficiently. Its support for powerful graph queries enables users to explore data relationships deeply, uncovering insights that would be less accessible in traditional database systems. Furthermore, Neptune's cloud-native features offer the reliability, scalability, and security essential for enterprise-grade applications.
In the next section, we will guide you through the process of implementing your knowledge graph using AWS Neptune, covering everything from initial setup to data integration and querying.
Overview to Implementing AWS Knowledge Graphs
Implementing a knowledge graph with AWS Neptune involves a series of steps, from setting up your AWS environment to integrating data and querying your graph. This guide will walk you through the process, ensuring you have a clear path to follow for successful implementation.
Setting Up AWS Neptune
- AWS Account and IAM Configuration: Ensure you have an AWS account. Set up AWS Identity and Access Management (IAM) roles and policies for Neptune to secure access and operations.
- Network and Security Settings: Configure VPC, subnets, and security groups for your Neptune instance to ensure secure and reliable access.
- Launching Neptune: Navigate to the AWS Management Console, locate the Neptune service, and launch a new Neptune instance. Choose the appropriate instance type based on your workload and performance requirements.
Data Integration into Neptune
- Data Preparation: Organize your data, ensuring it's in a format compatible with Neptune (e.g., CSV for bulk loading into a Property Graph model or RDF for semantic knowledge graph models).
- Data Loading: Use AWS's data loading tools to import your data into Neptune. Neptune supports bulk loading for efficient data ingestion.
Building the Knowledge Graph
- Graph Model Selection: Choose between Property Graph and RDF, depending on your data's nature and the queries you plan to run.
- Schema Design: Define your graph's schema, considering entities, relationships, and properties that represent your data domain.
- Vertex and Edge Creation: Start creating vertices (nodes) and edges (relationships) to build your graph structure. Utilize Neptune's support for Gremlin or SPARQL for these operations.
Querying Your Knowledge Graph
- Query Language Mastery: Familiarize yourself with Gremlin or SPARQL to effectively query your graph. Each language offers unique capabilities tailored to different graph operations.
- Advanced Queries: Implement complex queries to navigate your graph, uncovering deep insights through pattern matching, traversals, and aggregations.
Monitoring and Optimization
- Neptune Console: Use the AWS Management Console to monitor your Neptune instance's performance, adjusting resources as needed.
- Query Optimization: Analyze query performance and optimize as necessary to ensure efficient data retrieval and processing.
Best Practices for AWS Knowledge Graph Implementation
- Security First: Always prioritize security settings and IAM configurations to protect your data.
- Iterative Development: Start small with your graph and iteratively expand, allowing for adjustments based on initial findings and performance metrics.
- Leverage AWS Resources: Utilize AWS documentation, tutorials, and forums for additional support and insights during your implementation journey.
Implementing a knowledge graph with AWS Neptune is a powerful way to harness the potential of graph-based data storage and querying. By following these steps and best practices, you'll be well on your way to unlocking new insights and efficiencies within your data.
Advanced Techniques in AWS Knowledge Graph Optimization
After successfully deploying your AWS Knowledge Graph using Neptune, the next step is to refine and optimize its performance and scalability. This section introduces advanced techniques to enhance the efficiency of your knowledge graph, ensuring it delivers the speed, reliability, and insights required by your applications.
Graph showing results of performance optimization techniques for AWS knowledge graphs.
Performance Tuning for Neptune- Indexing Strategies: Implement indexing on vertices and edges based on your query patterns. Proper indexing can significantly reduce query execution times.
- Query Optimization: Analyze your query performance using Neptune's query plan explanation feature. Optimize your queries by restructuring them or adjusting your graph model to avoid costly operations.
- Partitioning Your Graph: For large graphs, consider partitioning your data across multiple Neptune instances. This can improve performance by distributing the load and allowing parallel processing.
Scalability Enhancements
- Vertical and Horizontal Scaling: Utilize Neptune's support for both vertical scaling (upgrading instance sizes) and horizontal scaling (adding read replicas) to manage increased loads and ensure high availability.
- Connection Pooling: Implement connection pooling on the client side to reduce the overhead of establishing connections to Neptune, enhancing the overall throughput of your application.
Advanced Data Integration Techniques
- Real-time Data Streaming: Integrate Neptune with AWS services like Kinesis for real-time data streaming into your knowledge graph. This enables dynamic updates and ensures your graph reflects the latest data.
- Utilizing AWS Lambda for Data Transformation: Leverage AWS Lambda to preprocess data before it enters Neptune, such as transforming data formats or applying business logic, for cleaner and more efficient data integration.
Ensuring High Availability and Disaster Recovery
- Backup and Restore: Regularly back up your Neptune cluster to S3, enabling quick restoration in case of data loss. Automate this process using AWS Backup for operational efficiency.
- Multi-Region Deployment: Deploy your Neptune cluster across multiple AWS regions to ensure high availability and disaster recovery. This strategy protects against region-specific failures and provides low-latency access across geographies.
Best Practices for Knowledge Graph Optimization
- Continuous Monitoring: Regularly monitor your Neptune instance's performance metrics. Utilize AWS CloudWatch for real-time monitoring and alerts.
- Query Caching: Implement caching mechanisms for frequently run queries to reduce load and improve response times.
- Use of Gremlin or SPARQL Extensions: Explore Neptune's support for Gremlin and SPARQL extensions for more efficient graph traversals and queries.
Optimizing your AWS Knowledge Graph is an ongoing process that involves regular monitoring, tuning, and adapting to new data and use cases. By employing these advanced techniques, you can ensure that your knowledge graph remains a robust, scalable, and insightful asset for your organization.
Real-World Applications of AWS Knowledge Graphs
The versatility and power of AWS knowledge graphs, powered by Neptune, extend across various industries, driving innovation and creating value by uncovering hidden relationships and insights within data.
The impact and potential of AWS knowledge graphs in different scenarios
Financial Services: Fraud Detection and Risk Management
In the financial sector, AWS knowledge graphs are revolutionizing fraud detection and risk management. By mapping transactions, customer interactions, and external data sources, these graphs can identify unusual patterns indicative of fraudulent activity or high-risk profiles, enabling proactive measures and safeguarding assets.
Healthcare: Patient Care and Research
AWS knowledge graphs facilitate comprehensive patient care and advanced medical research by integrating diverse data sources, such as electronic health records (EHRs), genomic data, and clinical studies. This holistic view supports personalized medicine, accelerates drug discovery, and enhances patient outcomes through more informed decision-making.
Retail and E-commerce: Personalization and Recommendation Engines
In retail and e-commerce, AWS knowledge graphs power sophisticated personalization and recommendation engines. By understanding customer preferences, purchase history, and product relationships, businesses can offer tailored shopping experiences, driving engagement, satisfaction, and sales.
Media and Entertainment: Content Discovery and Recommendation
For media and entertainment companies, AWS knowledge graphs enable dynamic content discovery and recommendation systems. By analyzing viewer behavior, content attributes, and social interactions, these graphs deliver personalized content suggestions, enhancing user engagement and loyalty.
Telecommunications: Network Optimization and Customer Service
In telecommunications, AWS knowledge graphs are used for network optimization and enhancing customer service. They provide insights into network performance, customer usage patterns, and service issues, facilitating efficient resource allocation, predictive maintenance, and improved customer experiences.
Harnessing AWS Knowledge Graphs for Your Business
The key to leveraging AWS knowledge graphs lies in understanding the unique challenges and opportunities within your industry. By thoughtfully integrating and analyzing your data, you can unlock transformative insights and drive significant business value. Whether optimizing operations, enhancing customer experiences, or accelerating innovation, AWS knowledge graphs offer a powerful tool to propel your organization forward.
Future Trends and Developments in Knowledge Graph Technology
As we look ahead, the field of knowledge graph technology, particularly within the AWS ecosystem, is poised for significant advancements and broader applications. This section explores emerging trends and future developments that will shape the evolution of AWS knowledge graphs, offering a glimpse into what's next for this transformative technology.
Embracing AI and Machine Learning Integration
AWS is continuously enhancing Neptune to better integrate with AI and machine learning (ML) services, such as Amazon SageMaker. This integration enables more sophisticated analytics and predictions, leveraging the rich semantic relationships within knowledge graphs to drive AI-powered insights and decision-making.
Graph Neural Networks (GNNs) and Knowledge Graphs
The intersection of graph neural networks (GNNs) and knowledge graphs represents a frontier in data analysis and interpretation. AWS's investment in GNNs will allow for deeper learning from graph data, unlocking new capabilities in pattern recognition, anomaly detection, and predictive analytics within knowledge graphs.
Scalability and Performance Improvements
As the demand for knowledge graphs grows, AWS is focusing on scalability and performance enhancements for Neptune. Future developments may include more efficient data storage formats, faster query processing algorithms, and enhanced support for distributed graph processing to handle ever-increasing data volumes and complexity.
Expanding the Ecosystem of Graph Data Sources
The integration of diverse data sources is crucial for enriching knowledge graphs. AWS is likely to expand its capabilities for seamlessly incorporating data from various AWS services and external sources, making it easier to build comprehensive and up-to-date knowledge graphs.
Enhanced Security and Compliance Measures
As knowledge graphs become more central to business operations, ensuring their security and compliance with regulatory standards is paramount. AWS will continue to strengthen Neptune's security features, including encryption, access controls, and compliance certifications, to meet the stringent requirements of different industries.
Preparing for the Future of Knowledge Graphs
Staying ahead in the rapidly evolving field of knowledge graph technology requires continuous learning and experimentation. Developers and organizations should keep abreast of AWS updates, participate in community forums, and explore new use cases to fully leverage the potential of AWS knowledge graphs in the future.
Conclusion: The Impact of AWS on Knowledge Graph Evolution
The exploration of AWS knowledge graphs through the lens of AWS Neptune has revealed a vast landscape of opportunities for data organization, analysis, and insight generation. As we've navigated from foundational concepts to advanced optimization techniques, and through real-world applications to future trends, the transformative potential of knowledge graphs in the AWS ecosystem has been clearly illuminated.
The Broadening Horizon of Knowledge Graphs
AWS's commitment to evolving Neptune and integrating it with a wider array of services promises to broaden the horizon for knowledge graphs. The convergence of traditional data management techniques with advanced AI and machine learning capabilities is set to redefine what's possible, pushing the boundaries of insight, efficiency, and innovation.
Empowering Organizations Across the Globe
The impact of AWS on knowledge graph evolution is profound, empowering organizations across industries to harness complex data relationships like never before. Whether in finance, healthcare, retail, or telecommunications, the ability to dynamically map and analyze data relationships is becoming a critical driver of success.
Looking Forward
As AWS continues to innovate and expand its graph database offerings, the future of knowledge graphs looks bright. Organizations and developers are encouraged to stay engaged with AWS's evolving technology landscape, leveraging these powerful tools to unlock new levels of understanding and strategic advantage.
The journey of building intelligent knowledge graphs with AWS is just beginning. With the right approach, tools, and vision, the possibilities are limitless. As we look to the future, one thing is clear: the role of AWS in shaping the next generation of knowledge graphs is undeniable, promising a more connected, insightful, and intelligent world.
About the Author
Fabian Silva is a passionate applied mathematician with over ten years experience in software engineering and architecture for data visualization systems.
FAQ
How do knowledge graphs handle real-time data updates?
Knowledge graphs built with AWS Neptune can handle real-time data updates by integrating with services like AWS Kinesis or AWS Lambda. These services allow for the real-time ingestion of streaming data into your knowledge graph, ensuring that the data remains up-to-date as new information becomes available.
Can I visualize a knowledge graph built with AWS Neptune?
Yes, you can visualize your AWS Neptune knowledge graph by using third-party tools such as Amazon QuickSight, Tom Sawyer Perspectives, or open-source tools like Graphistry and Gephi. These tools allow you to create visual representations of the nodes and edges in your graph, helping to analyze and explore relationships in an intuitive, visual format.
How does AWS Neptune compare to other graph databases?
AWS Neptune is designed to be fully managed, offering built-in features like automatic scaling, backup and restore, and high availability across multiple availability zones. Compared to self-hosted or other managed graph databases, Neptune reduces the operational overhead. However, choosing between AWS Neptune and other graph databases like Neo4j or TigerGraph depends on your specific requirements, including your preference for supported query languages, licensing, and scalability features.
How can I migrate data from a traditional relational database to a knowledge graph in AWS Neptune?
To migrate data from a relational database to a knowledge graph, you first need to transform the data into a graph-friendly format. This involves identifying entities and relationships within your relational data. AWS provides tools like AWS Glue for ETL (extract, transform, load) processes and Neptune Bulk Loader for importing large datasets into Neptune. You may also need to map the relational schema to a graph structure (nodes and edges) based on your use case.
Can AWS Neptune be used for hybrid cloud architectures?
Yes, AWS Neptune can be integrated into hybrid cloud architectures. AWS provides services like AWS Direct Connect and AWS VPN to securely extend your on-premises infrastructure to the AWS cloud, allowing you to incorporate Neptune into a broader hybrid cloud strategy. This is particularly useful for businesses that need to keep certain data on-premises due to regulatory or operational requirements.
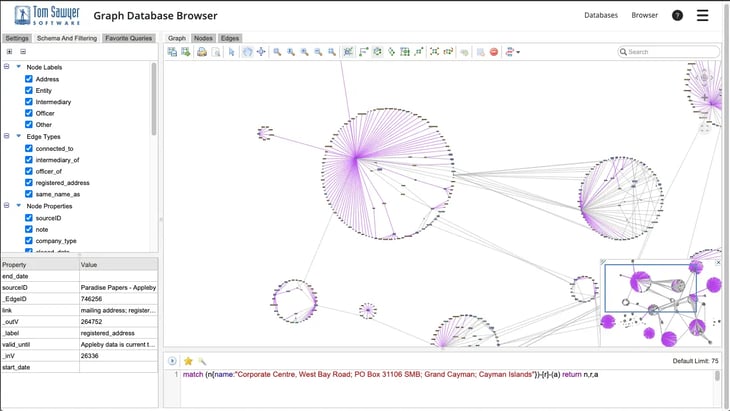
How can I visualize my AWS Neptune knowledge graph using Tom Sawyer Software?
Tom Sawyer Software provides powerful tools for graph visualization, including Tom Sawyer Perspectives, which can be used to visualize, interact with, and analyze the complex relationships in your AWS Neptune knowledge graph. By connecting Neptune to Tom Sawyer, you can generate customizable visualizations that help you better understand your data’s structure, relationships, and insights. The software supports a wide range of visualization techniques such as node-link diagrams, hierarchical views, and geographic layouts.
Submit a Comment