
Thanos Giannakis
Senior Product Development Engineer
What is Neo4j?
Neo4j is at the forefront of database technology with its graph-based approach, offering a flexible and intuitive way to represent complex networks of data. Unlike traditional relational databases that store data in rigid, table-like structures, Neo4j utilizes nodes and relationships to map out data in a way that mirrors real-world scenarios. This graph-based model allows for more efficient querying and data retrieval, especially when dealing with intricate connections between data points.
A large social network graph.
Graph databases like Neo4j are particularly well-suited for applications requiring advanced data analysis and insight discovery, such as social networks, recommendation engines, and fraud detection systems. By enabling direct, semantically meaningful relationships between data nodes, Neo4j facilitates a depth of analysis that is difficult to achieve with other database systems.
Benefits of Using Neo4j Database
The adoption of Neo4j brings several key benefits to organizations and developers dealing with connected data.
Superior Performance and Scalability:- The graph-based model outperforms traditional databases in speed and efficiency.
- Notable in real-time recommendation systems, network and IT operations, and fraud detection.
- Enables quick navigation and analysis of deep relationships.
-
Scales horizontally and vertically by distributing large volumes of data across multiple servers.
- Schema-less nature allows for evolving data models without significant refactoring.
- Supports rapid application development and adapts to changing business requirements.
- Comprehensive documentation and a vibrant community.
- A plethora of libraries and tools for developing sophisticated applications.
- Lower development overhead.
- Ensures data consistency.
- Provides reliability for enterprise applications.
Implementing a Neo4j Knowledge Graph
Implementing a Neo4j Knowledge Graph involves several critical steps, from initial setup and configuration to data modeling and integration. This process leverages Neo4j's capabilities to create a dynamic and interconnected data structure that can efficiently store, query, and manage complex relationships between data entities. Knowledge graphs built with Neo4j offer unparalleled insights into data by making relationships with first-class citizens and enabling powerful query capabilities and analytics that are not possible with traditional relational databases.
Building a Knowledge Graph in Neo4j
Building a knowledge graph in Neo4j involves a systematic approach to data modeling, data import, and leveraging Cypher queries for data analysis. The power of a knowledge graph lies in its ability to not just store data but to represent complex relationships and connections between data entities, providing deep insights and facilitating advanced data interactions.
The first step in building a knowledge graph is to carefully design the data model. This includes identifying the key entities (nodes) and their relationships, understanding the properties that should be associated with each, and determining how these elements interact within the broader data landscape. A well-thought-out data model serves as the foundation for a robust and scalable knowledge graph.
Once the model is established, the next step involves importing data into Neo4j and applying semantics. This could come from various sources, such as CSV files, existing databases, or direct input. Neo4j offers several tools and methods for data importation, ensuring flexibility and efficiency in populating the knowledge graph.
With the data in place, the focus shifts to querying and analyzing the graph. Neo4j's Cypher query language is instrumental in this phase, enabling sophisticated queries that can navigate deep relationships, perform pattern matching, and execute complex analyses. This capability allows users to extract meaningful insights from their data, uncover hidden patterns, and make data-driven decisions with confidence.
Building a knowledge graph in Neo4j is a dynamic process that combines careful planning, efficient data handling, and powerful querying to unlock the full potential of connected data.
Data Modeling for a Knowledge Graph
Data modeling for a Neo4j knowledge graph is a critical step that determines how effectively the graph can represent and query real-world relationships. A good data model in Neo4j translates complex and interconnected information into a graph structure of nodes, relationships, and properties that accurately reflects the nuances of the data.
The process begins by identifying the main entities of interest, which become the nodes in the graph, such as people, products, or events. These nodes are then connected through relationships that represent how entities interact with one another, such as "FRIEND_OF" or "ATTENDED." Each node and relationship can have properties that store additional details, providing a rich data context.
Effective data modeling in Neo4j requires a balance between granularity and simplicity. Too many node labels or relationship types can complicate the graph and make queries less efficient, while too few can oversimplify the data and obscure valuable insights. The goal is to create a model that is intuitive, scalable, and capable of supporting complex queries and analytics.
By carefully designing the graph schema, developers can ensure that their Neo4j knowledge graph is well-structured, query-friendly, and ready to provide deep insights into the data.
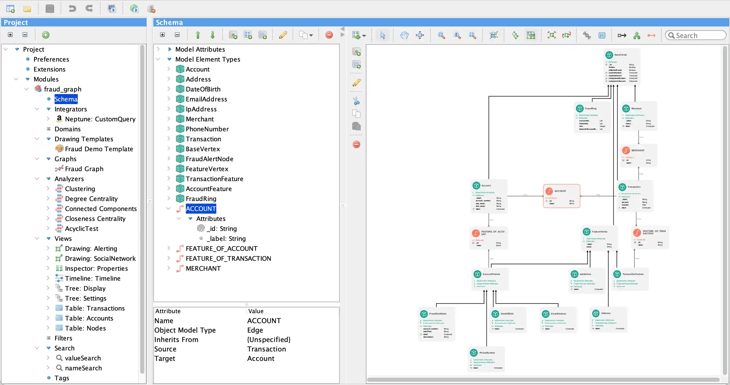
A fraud detection graph schema.
Using Indexes to Improve Query Performance
In Neo4j, indexes significantly enhance query performance, especially for large-scale knowledge graphs where efficient data retrieval is crucial. Indexes in Neo4j are used to quickly locate nodes or relationships by their properties, reducing the time it takes to execute queries that filter on these attributes.
Proper use of indexes is vital for maintaining high performance in a Neo4j database. However, it's important to balance the number of indexes with the overall workload, as each index can add overhead to write operations. Strategic index creation, focused on the most frequently queried properties, ensures that the knowledge graph remains responsive and efficient.
Integrating with External Data Sources
Integrating Neo4j with external data sources is a powerful feature that allows for the enrichment of the knowledge graph with diverse data sets. This integration can take various forms, including direct database connections, ETL processes, or real-time data streams, facilitating a dynamic and comprehensive data environment.
Neo4j offers tools and connectors for seamless integration with popular data sources, such as relational databases, NoSQL stores, and cloud services. This interoperability enables the ingestion of external data into the Neo4j graph, where it can be linked with existing nodes and relationships, providing a richer context and deeper insights.
For organizations, the ability to integrate external data sources with their Neo4j knowledge graph allows for the continuous evolution of the graph as new data becomes available, ensuring that the knowledge graph remains up-to-date and reflective of the real-world systems it models.
Advanced Features and Optimization of Neo4j Knowledge Graphs
Neo4j's advanced features and optimization capabilities enable developers and data architects to enhance the performance, scalability, and functionality of their knowledge graphs. These features are crucial for maintaining high performance as the size and complexity of the data grow.
One of Neo4j's advanced features is its support for graph algorithms, which are integral for uncovering deep insights within complex networks. Algorithms for pathfinding, centrality, and community detection allow users to analyze relationships at scale, identify influential nodes, and discover clusters or groups within the graph. By leveraging these algorithms, businesses can optimize routes, understand customer segments better, and detect fraud patterns.
Optimization in Neo4j also extends to query performance. Besides indexing, which significantly improves query speed, Neo4j offers query plan caching and fine-tuning options. These allow repeated queries to run faster and enable developers to optimize how queries access the graph, reducing execution times.
Furthermore, Neo4j's architecture supports both vertical and horizontal scaling. Vertical scaling increases the power of a single server, while horizontal scaling, or sharding, distributes the graph across multiple servers, improving performance and fault tolerance. This scalability ensures that Neo4j can handle growing data volumes and increasingly complex queries without degradation in performance.
For organizations looking to maximize their investment in knowledge graphs, Neo4j's advanced features and optimization techniques provide a robust framework for building, querying, and analyzing connected data at scale. These capabilities ensure that as the demands on the graph increase, Neo4j can continue to deliver fast, accurate, and insightful results.
Working with Large Datasets
Handling large datasets in Neo4j requires strategic planning and the use of specific features designed to manage and query data efficiently at scale. As data volume grows, the challenges around performance, storage, and analysis become more pronounced. However, Neo4j's architecture and tools are well-suited to address these challenges, ensuring that knowledge graphs remain performant and scalable.
For large datasets, one of the key strategies is to optimize data model design. A well-designed model minimizes redundancy and ensures that queries can traverse the graph efficiently. This might involve structuring nodes and relationships in a way that reduces the depth of queries needed to extract valuable insights.
Partitioning the graph can also improve performance with large datasets. By dividing the graph into smaller, manageable subgraphs, queries can be executed more quickly. This approach, combined with Neo4j's capabilities for horizontal scaling, allows for the effective distribution of the data across multiple servers.
Indexing is another critical technique for enhancing query performance in large graphs. By indexing frequently accessed nodes and properties, Neo4j can rapidly retrieve relevant data, significantly reducing query execution times. Proper use of indexes is essential for maintaining high performance as the graph grows.
Additionally, Neo4j provides tools for efficient data import and export, supporting bulk operations that are essential when working with large datasets. These tools are designed to minimize the impact on the database's operational performance, ensuring that data can be updated or migrated with minimal downtime.
By leveraging Neo4j's features for handling large datasets, organizations can maintain high-performance knowledge graphs that are capable of delivering real-time insights, even as data volume and complexity increase.
Scaling and Distribution Techniques
Scaling and distribution are critical considerations for managing large datasets in Neo4j, ensuring that the database can accommodate growth without sacrificing performance. Neo4j supports both vertical and horizontal scaling, providing flexibility in how data is stored and accessed.
Vertical scaling, or scaling up, involves increasing the capacity of a single Neo4j instance by adding more CPU, RAM, or storage. This approach is straightforward and can significantly enhance performance for many applications. However, it has its limits based on the maximum capabilities of a single server.
Horizontal scaling, or scaling out, extends the database across multiple machines, distributing the load and data storage. Neo4j's causal clustering feature supports horizontal scaling by allowing multiple instances of the database to work together. This setup not only improves performance by distributing queries and transactions across the cluster but also enhances availability and fault tolerance.
Sharding, the distribution of data across different databases within the cluster, is another technique that can improve performance and scalability. By partitioning the graph into smaller, more manageable pieces, Neo4j can optimize query execution and reduce the overhead on any single server.
Implementing these scaling and distribution techniques requires careful planning and consideration of the specific needs of the application. However, when done correctly, they can ensure that a Neo4j database remains fast, efficient, and reliable, even as it grows to accommodate large datasets.
Security and Maintenance of Neo4j Knowledge Graphs
Ensuring the security and regular maintenance of Neo4j knowledge graphs is essential for protecting sensitive data and ensuring the database's optimal performance. As with any database system, a comprehensive approach to security helps prevent unauthorized access and potential data breaches, while routine maintenance tasks help identify and rectify issues before they impact performance or data integrity.
Security in Neo4j involves multiple layers, starting with authentication and authorization controls to manage access to the database. Neo4j supports role-based access control (RBAC), allowing administrators to define roles with specific permissions for different types of users, ensuring that individuals can only access data and perform actions appropriate to their roles.
Encryption is another critical aspect of Neo4j's security framework. Encrypting data in transit between the database and clients protects sensitive information from interception. For data at rest, encryption options ensure that stored data is inaccessible to unauthorized users, even if they gain physical access to the storage media.
In terms of maintenance, Neo4j provides tools and features to help administrators keep the database running smoothly. Regular monitoring of database performance metrics can help identify potential issues early, allowing for timely intervention.
Adopting best practices for security and maintenance not only protects the knowledge graph and its data but also ensures that the system remains reliable, performant, and available to support critical business applications.
Backup and Recovery
Backup and recovery are critical components of the overall maintenance strategy for Neo4j knowledge graphs. Regular backups ensure that data can be restored in case of corruption, loss, or a disaster, minimizing downtime and preventing permanent data loss.
Neo4j provides built-in tools for performing backups, supporting both online and offline backup strategies. Online backups can be performed without interrupting database service, allowing for regular backups to be scheduled without affecting database availability. Offline backups, while requiring database downtime, can ensure a consistent snapshot of the database at a point in time.
For large datasets, incremental backups may be preferred, as they only capture changes since the last backup, reducing storage requirements and backup time. It's important to test backup and recovery procedures regularly to ensure they work as expected and to store backup copies in a secure, off-site location to protect against site-specific disasters.
Recovery procedures should be well documented and practiced regularly to ensure that data can be quickly restored when needed. This includes not only restoring data from backups but also verifying the integrity of the restored data and reconciling any data changes that occurred since the last backup.
Implementing a robust backup and recovery plan is essential for maintaining the integrity and availability of Neo4j knowledge graphs, ensuring that critical data is protected against loss or corruption.
Automation of Maintenance and System Monitoring
Automating maintenance tasks and system monitoring is a best practice for efficiently managing Neo4j knowledge graphs, particularly as they scale. Automation can help ensure that routine maintenance tasks, such as backups, performance tuning, and security updates, are performed consistently and without manual intervention.
Using tools and scripts, administrators can schedule regular maintenance operations, such as database compaction and optimization, index rebuilding, and consistency checks. Automation of these tasks reduces the risk of human error and frees up administrators to focus on more strategic activities.
For system monitoring, automated tools can continuously track database performance metrics, such as query response times, memory usage, and disk space. These tools can alert administrators to potential issues before they impact the database's performance or availability, allowing for proactive intervention.
Adopting automation for maintenance and monitoring not only enhances the reliability and performance of Neo4j knowledge graphs but also contributes to a more efficient and effective database management strategy.
Innovative Applications of Neo4j Knowledge Graphs
Neo4j's flexibility and efficiency in handling connected data have spurred innovative applications across various fields, demonstrating the versatility and power of graph database technology. These applications not only solve traditional problems more effectively but also open up new avenues for exploration and innovation.
In the realm of social networking, Neo4j facilitates the analysis of complex user relationships, enabling platforms to offer more relevant content, suggest new connections, and enhance user engagement through personalized experiences. Its ability to quickly traverse the social graph allows for real-time recommendations and insights that are critical to the success of social platforms.
Supply chain optimization is another area where Neo4j provides companies with the ability to model their entire supply chain as a graph. This enables them to identify inefficiencies, predict potential disruptions, and optimize routes and inventories based on real-time data, significantly improving operational resilience and efficiency.
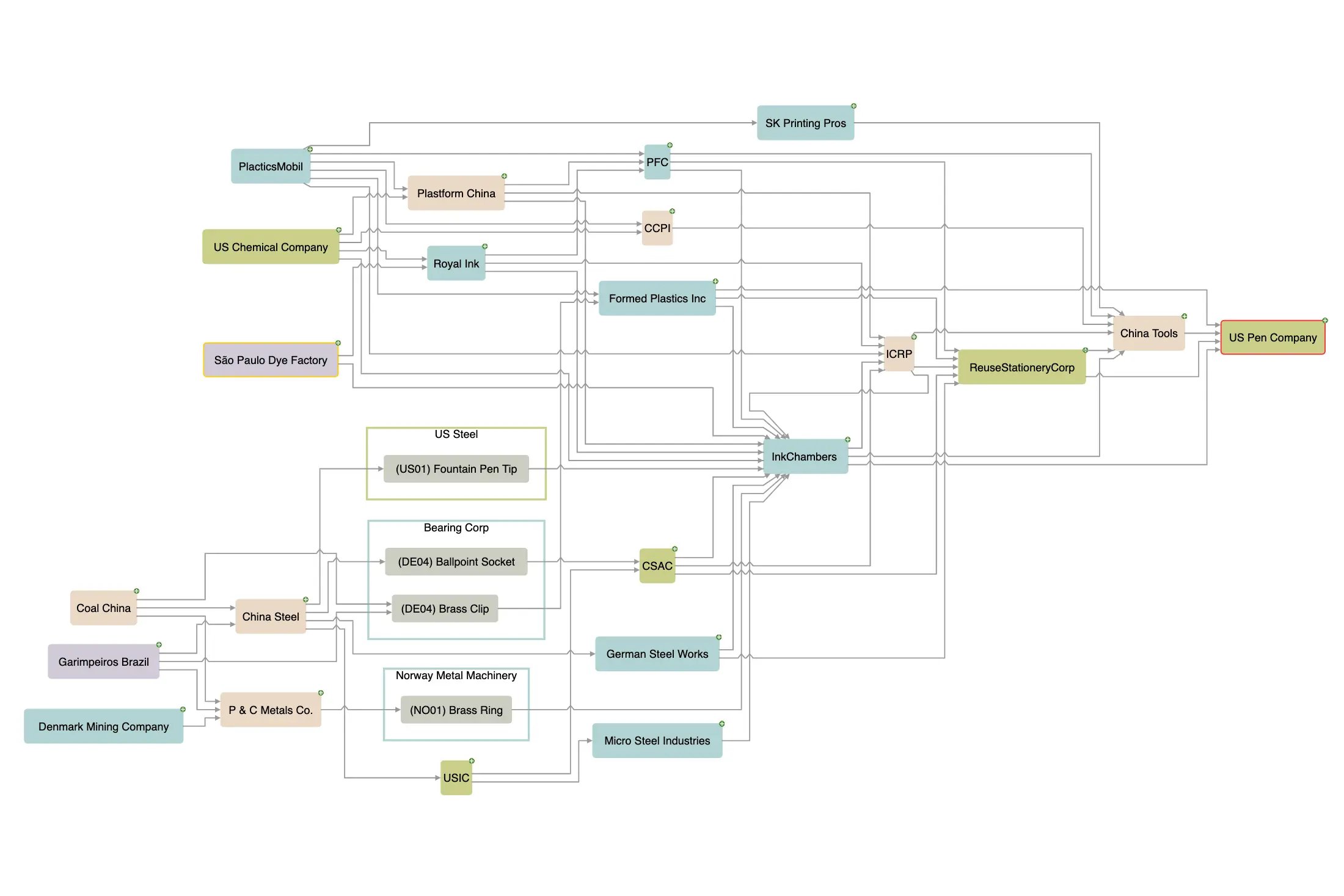
A supply chain knowledge graph.
Neo4j is also at the forefront of combating cyber threats. By modeling networks and transactions as graphs, security professionals can identify unusual patterns that may indicate fraud or cyber-attacks, enabling proactive measures to protect sensitive data and systems.
Furthermore, in scientific research, Neo4j is used to map complex relationships between genes, proteins, and diseases, accelerating the discovery of new treatments and understanding of genetic disorders. The ability to quickly explore these connections is revolutionizing biomedical research and paving the way for breakthroughs in personalized medicine.
As technology evolves, the innovative applications of Neo4j will continue to expand, driven by its ability to model, analyze, and visualize complex networks of relationships. This not only solves existing challenges more effectively but also enables entirely new approaches to data analysis and application development.
Fraud Detection and Risk Management
Neo4j plays a crucial role in fraud detection and risk management by leveraging its graph-based approach to uncover complex patterns and hidden relationships indicative of fraudulent activity. Traditional methods may struggle to connect disparate pieces of data that, when viewed through the lens of a graph, reveal suspicious behaviors and linkages.
In financial services, for example, Neo4j can track transactions across accounts and institutions in real time, identifying anomalies that suggest money laundering, identity theft, or fraudulent transactions. By visualizing the network of interactions, analysts can spot unusual patterns, such as circular transactions or rapid movements of funds, which might otherwise go unnoticed.
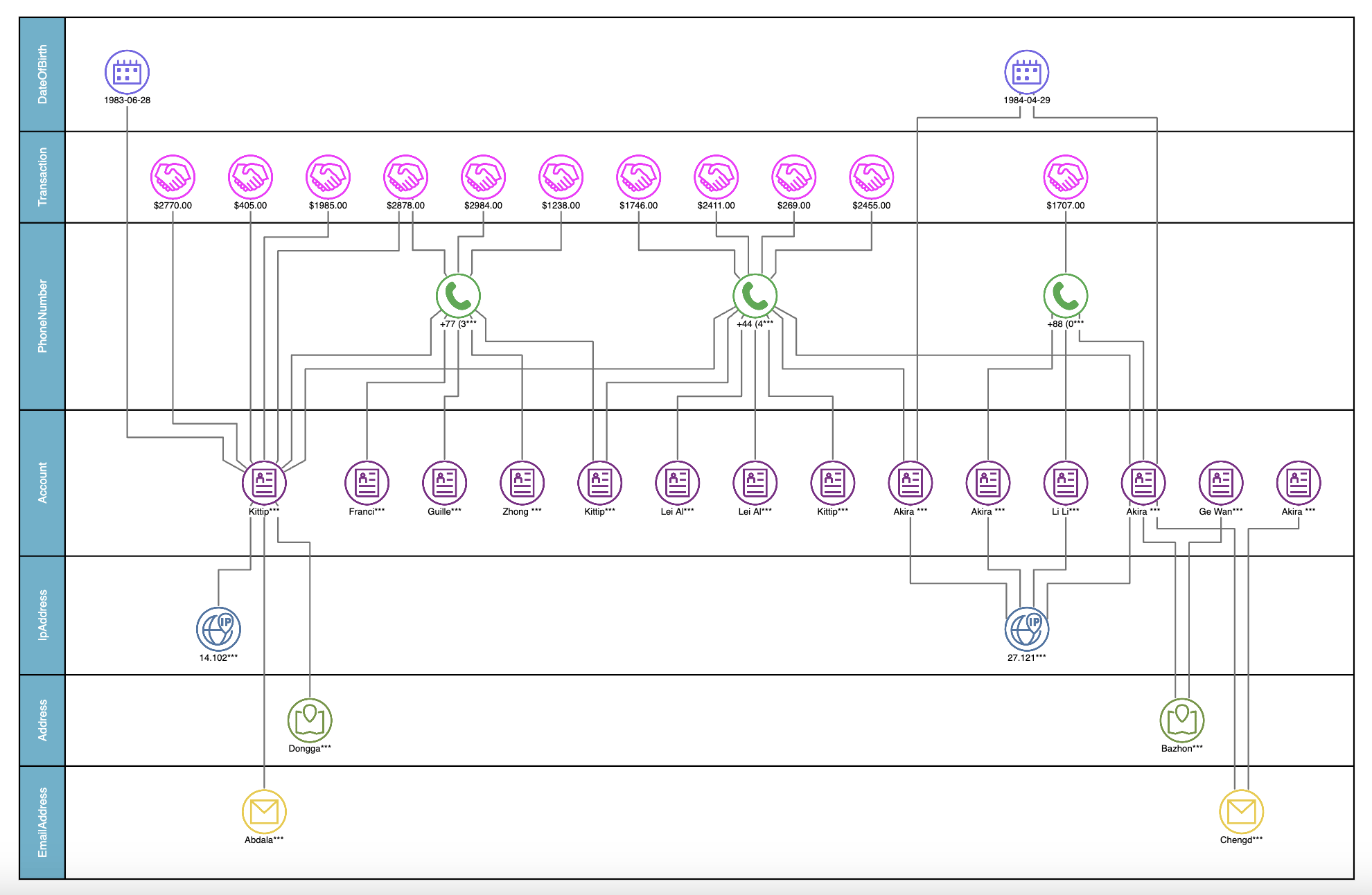
A knowledge graph of suspicious financial transactions.
The ability to dynamically analyze and visualize these relationships allows organizations to respond quickly to potential threats, minimizing financial losses and protecting customer data. Furthermore, Neo4j's flexibility in modeling risk scenarios enables companies to adapt their detection strategies as fraudsters evolve, ensuring that risk management systems remain robust and effective.
Future Trends and Development in Neo4j Technology
As we look toward the future of Neo4j technology, several key trends and developments stand out that are likely to shape the evolution of graph databases and their applications. These trends not only reflect the ongoing advancements in database technology but also the changing landscape of data management and analysis driven by the increasing complexity and interconnectedness of digital information.
- Integration with AI and Machine Learning: Neo4j's future will see deeper integration with AI and machine learning technologies. Graph databases offer a natural way to enrich AI models with complex, relationship-driven data, improving the accuracy and effectiveness of predictive analytics, natural language processing, and cognitive applications.
- Graph Algorithms and Analytics Enhancements: Continued development of advanced graph algorithms will unlock new capabilities in pattern recognition, anomaly detection, and complex network analysis. This will empower organizations to extract more nuanced insights from their data, facilitating breakthroughs in research, cybersecurity, and business intelligence.
- Improved Scalability and Performance: As data volumes continue to grow, scalability and performance optimization will remain focal points for Neo4j development. Enhancements in distributed computing, in-memory processing, and dynamic clustering will enable Neo4j to handle larger graphs and more complex queries with increased efficiency.
- Enhanced Security Features: Security will continue to be a critical concern, driving enhancements in encryption, access control, and data privacy within Neo4j. As graph databases become central to more business operations, ensuring the integrity and confidentiality of graph data will be paramount.
- Cloud-Native and Multi-Cloud Support: The shift towards cloud-native architectures and the need for multi-cloud strategies will influence Neo4j's development. Enhanced support for deployment and management across different cloud environments will ensure flexibility and resilience for Neo4j applications.
- Community and Ecosystem Growth: The Neo4j community and ecosystem are set to expand further, fostering innovation and collaboration. An increase in third-party tools, libraries, and integrations will enhance Neo4j's usability and accessibility for a wider range of users and use cases.
- Standards and Interoperability: Efforts towards standardization and interoperability among graph databases will gain momentum. This will facilitate smoother data sharing and migration, enabling organizations to leverage the best of graph technology without being locked into a single vendor.
These trends underscore the dynamic and evolving nature of Neo4j technology. As we move forward, Neo4j is poised to play an even more integral role in how we store, analyze, and derive value from data, driving innovation across industries and applications.
About the Author
Thanos Giannakis, is a results-driven professional with over 9 years of expertise in software development, graph database integrations, and graph based solutions. As a technical lead engineer, he orchestrates the development of robust software systems that harness the power graph databases to extract insights from complex data structures. Thanos holds a Master of Software Engineering degree from the University of Computer Science Department in Crete.
FAQ
How does Neo4j differ from other graph databases, and why is it so popular?
Neo4j stands out for its mature and powerful ecosystem, including a robust query language (Cypher), strong community support, and a proven track record of use across industries. While there are other graph databases, Neo4j’s rich feature set, scalability, and enterprise-grade support make it popular for businesses looking to handle complex connected data efficiently. Additionally, its ability to handle both transactional and analytical workloads seamlessly is a key advantage.
How can organizations measure the ROI of implementing a Neo4j knowledge graph?
Measuring the ROI involves tracking key metrics such as improved query performance, faster decision-making, reduced time spent on data preparation, and enhanced data insights. Additionally, the reduction in fraud detection time, increased accuracy in recommendation systems, and more efficient supply chain management are tangible ways to quantify the value. Over time, increased innovation and the ability to make data-driven decisions more efficiently can significantly enhance the overall return on investment.
What are the best practices for scaling Neo4j in a production environment?
Scaling Neo4j in production requires strategic use of both vertical (adding more resources to a single server) and horizontal scaling (distributing data across multiple servers). Key best practices include partitioning large graphs, using Neo4j’s causal clustering for high availability, and implementing sharding techniques to distribute workloads. Regular monitoring, query optimization, and leveraging Neo4j’s advanced features like graph algorithms will ensure smooth scaling as datasets grow.
How does Neo4j ensure the security and privacy of sensitive data within knowledge graphs?
Neo4j incorporates several layers of security, including role-based access control (RBAC), encryption of data both in transit and at rest, and comprehensive auditing tools. This ensures that only authorized users can access specific datasets and sensitive information is protected from unauthorized access. Furthermore, regular updates and adherence to compliance standards such as GDPR ensure that privacy requirements are met, particularly in industries like healthcare and finance.
What are the advantages of using Neo4j for managing supply chain logistics?
Neo4j’s graph-based approach allows for real-time visualization and optimization of supply chain networks by mapping out complex relationships between suppliers, products, distribution centers, and retailers. This helps businesses identify bottlenecks, streamline operations, and optimize routes for efficiency. Neo4j can also support predictive analysis by identifying potential disruptions in the supply chain, such as delays or inventory shortages, allowing companies to proactively adjust their operations. Modeling and analyzing these interconnected elements makes Neo4j ideal for supply chain management.
Submit a Comment