
Joshua Feingold, Austris Krastins
CTO, Senior Technical Design Director
The new dynamic data integrator tool in Tom Sawyer Perspectives 10.0 allows you to integrate your data in about 20 seconds. From there you can springboard from a Cypher or Gremlin-compatible database to a fully customized, interactive visualization application in only 100 seconds more!
If you are a DBA, data scientist, or data-centric app developer, you know that the world of data has changed a lot in the last five years. It has diversified from “always SQL in production” to include a meaningful amount of "schemaless" data in the form of property graphs, REST services, and document databases. Just like “serverless” still runs on servers, every schemaless database in a production environment still has a de facto schema. However, the database itself is not aware of or enforcing that schema, for good or for ill.
Until 10.0, Perspectives was a schema-first tool. We got good at pulling schemas out of data sources, even if they were nominally schemaless. We wrote custom application-level code to optimize operations that schema-first designs made awkward. Now that Perspectives is a schema-optional platform, that custom code is no longer needed, and we can pull off that two-minute prototype trick. Let’s see how the dynamic data integrator tool helps make that happen.
Dynamic Data Integration
Perspectives allows for extremely flexible mappings between databases and app-level models. In previous releases, this meant that you needed to establish bindings between query results and models on a per-attribute-per-type basis. While the function worked well, many users wanted to short circuit this process for a 1:1 data import. So, we added that capability and got some nice performance and capability boosts along the way.
Let’s imagine a simple database that has four node types stitched together with three edge types. Using an explicit data binding (the norm prior to 10.0), the user would specify seven different queries and map each to an individual data type. This gives extremely fine-grained control, but it can also lead to duplication of queries, both at design time and runtime.
For users that don’t need that level of detail in their data mappings (in our experience, this turns out to be most users), we now support Dynamic Bindings. You write one query that returns everything you are interested in, and Perspectives sorts out the results into data of the corresponding types.
This means you can explore the data in the database at design time without having to create a schema or explicitly define the data bindings. It also means you can execute one query instead of seven at runtime to improve application performance.
Automatic Bindings
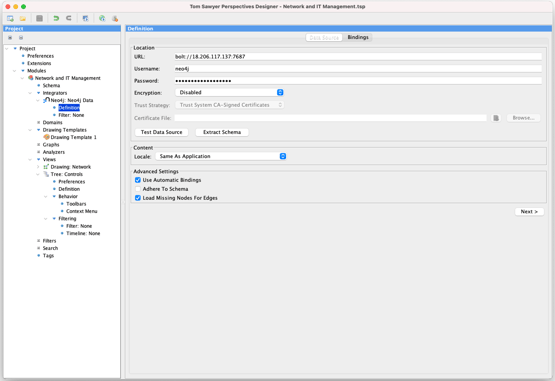
First you add an integrator to connect to your graph database. In this example, we use Neo4j. The new Automatic Bindings feature is turned on by default and you can fine-tune its behavior by using the advanced settings Adhere to Schema and Load Missing Nodes for Edges.
When Adhere to Schema is selected, the integrator ignores elements and attributes that are not part of your module’s schema. Imagine those seven node and edge types are a subset of fifty different types present in the database and you want to make sure you don’t import all that other stuff. This box handles that.
When Load Missing Nodes for Edges is selected, the integrator assumes that any time you load an edge, you want to know about its source and target and will go fetch them from the database. We turn this one on by default too.
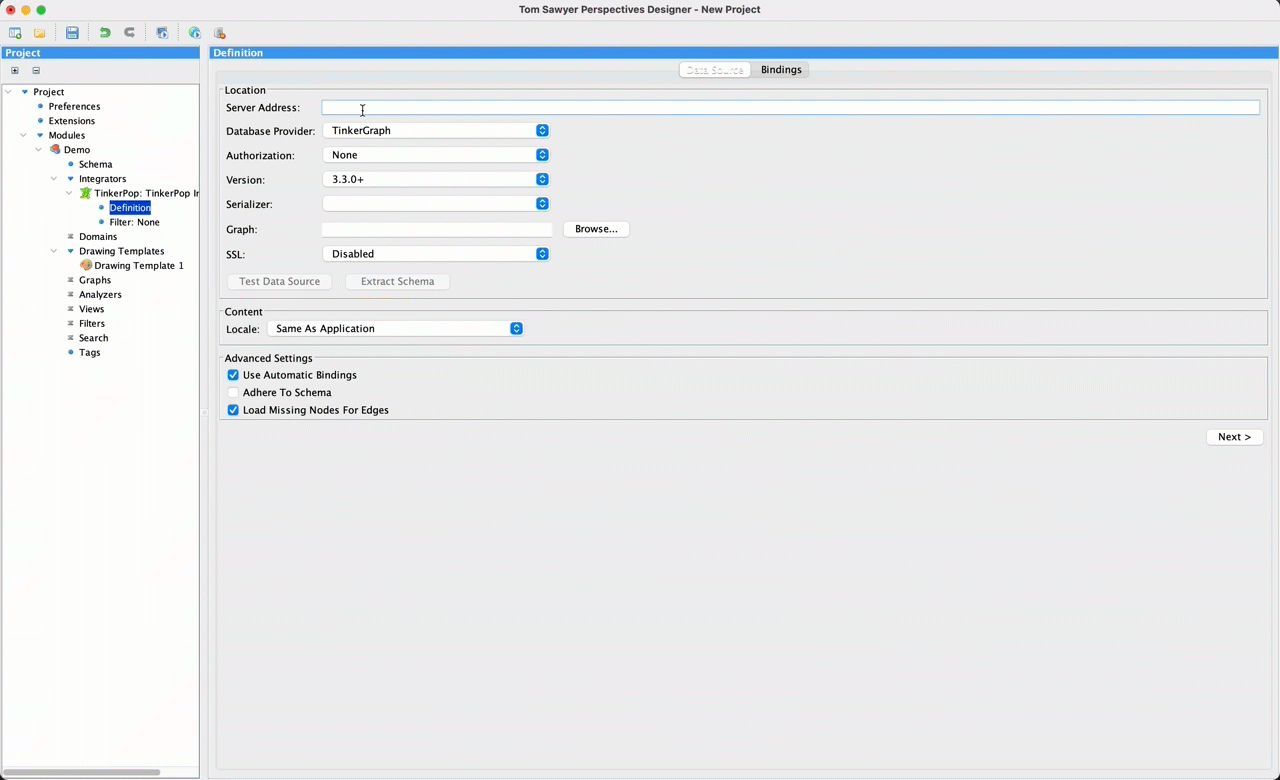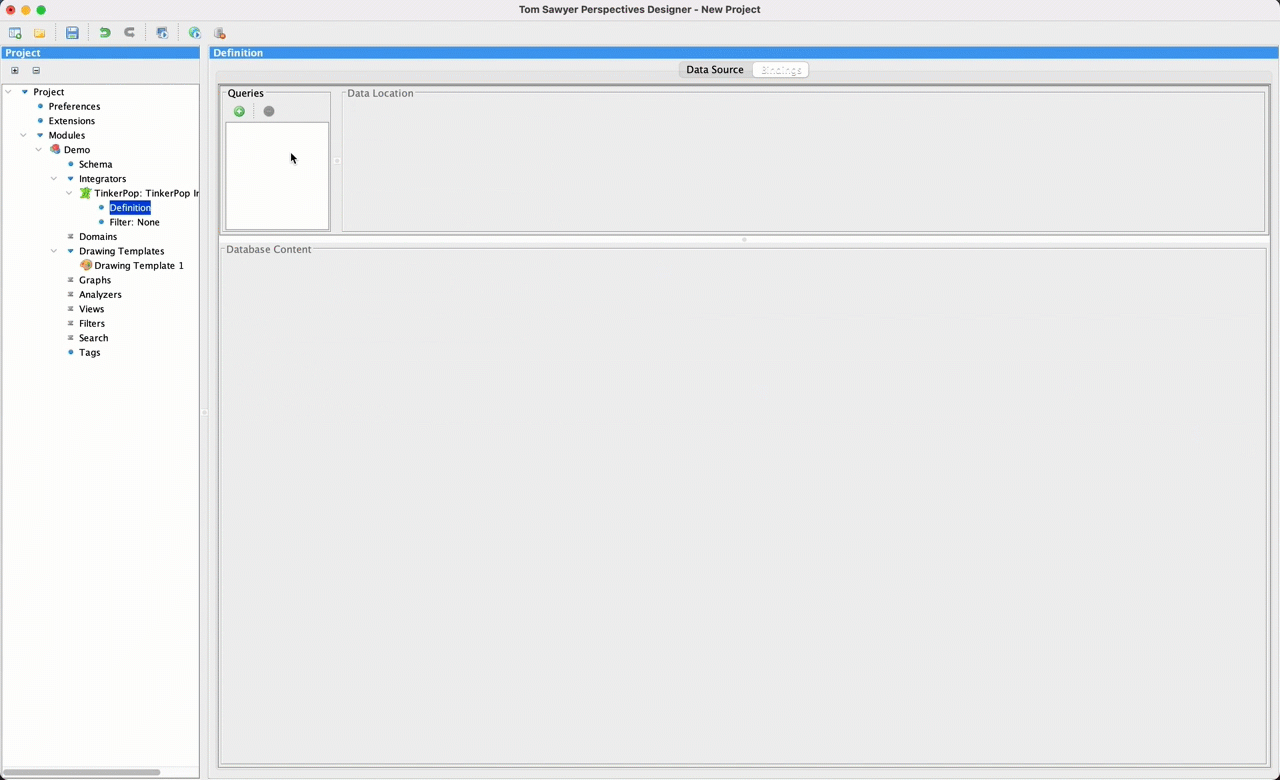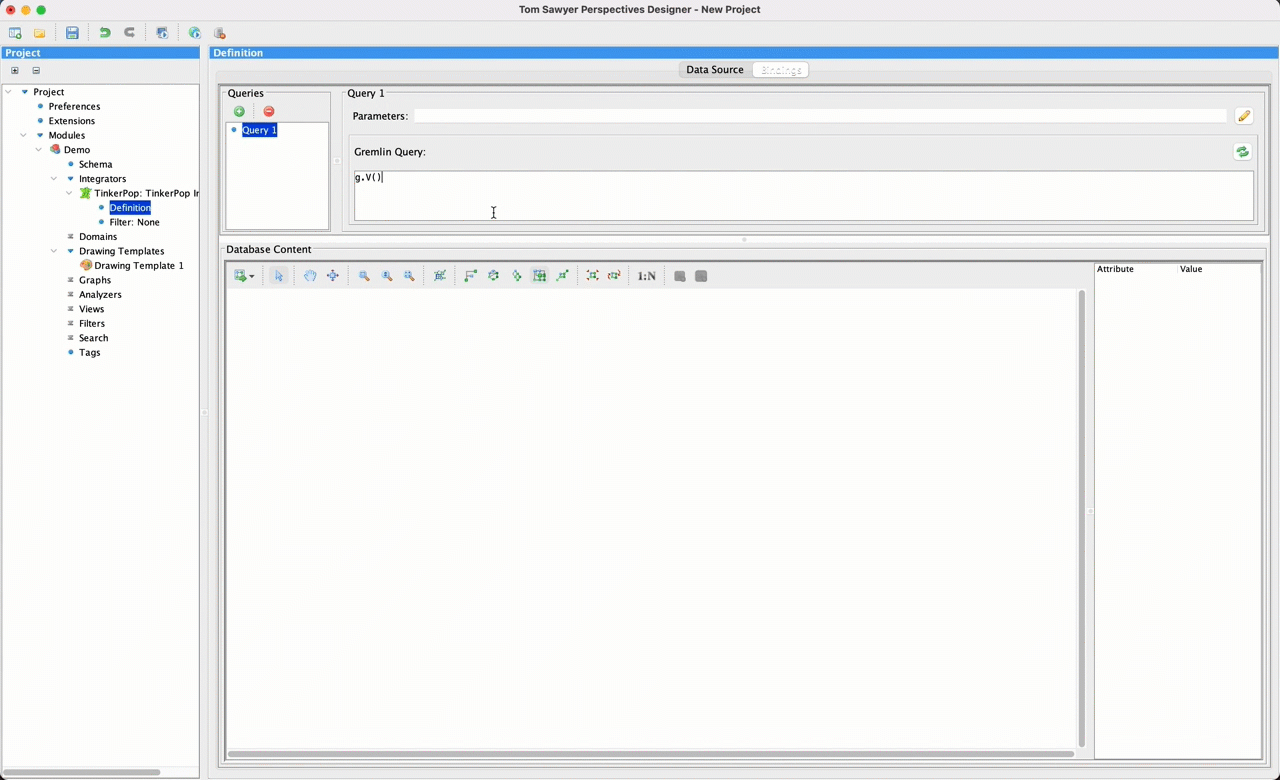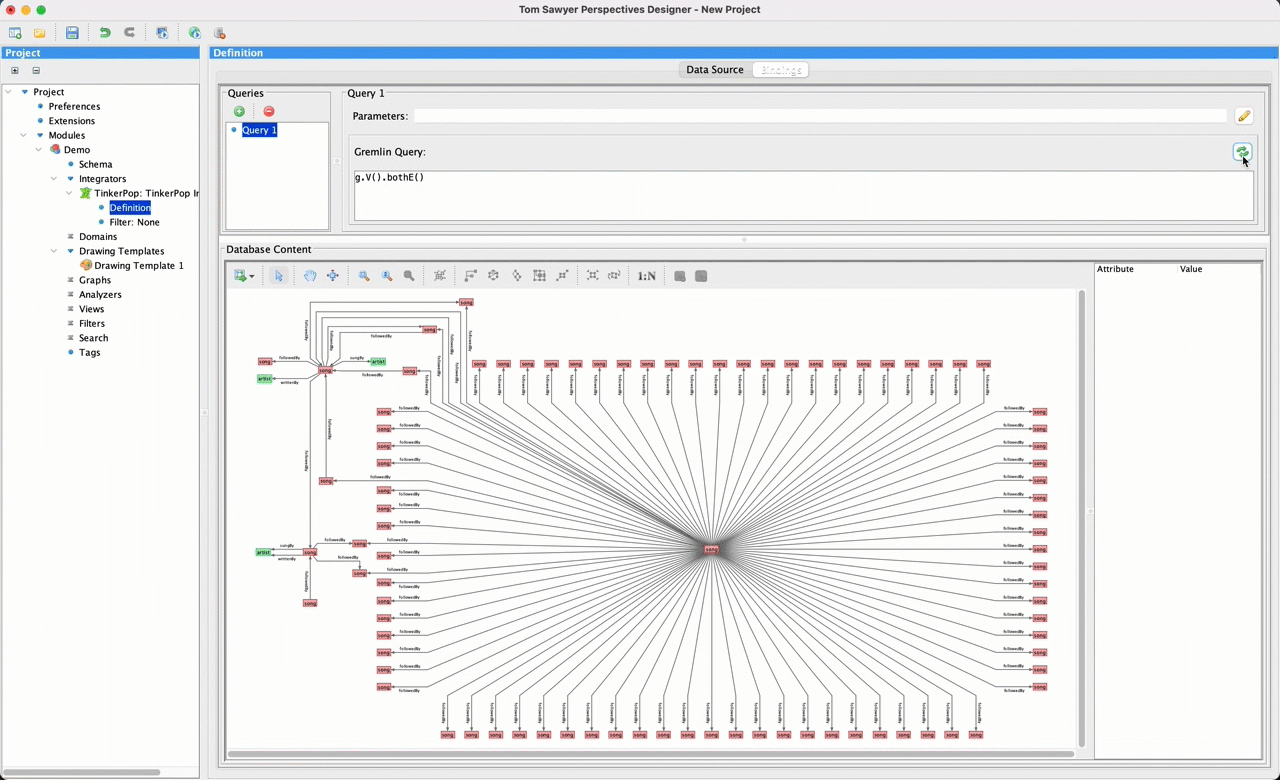
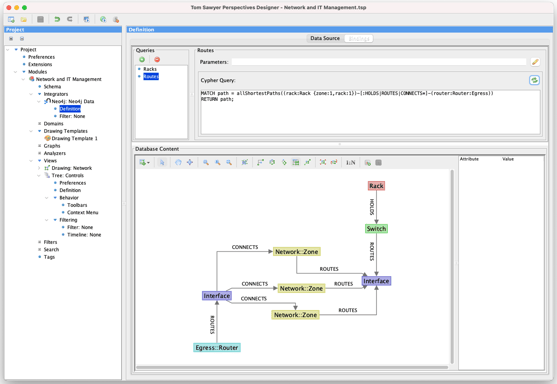
 Next, we move to the Bindings pane and add a new query. This query can return an arbitrary set of nodes, edges, and paths as well as some additional values. You see a small preview of the returned results as a graph drawing, where nodes are color-coded by their labels.
Next, we move to the Bindings pane and add a new query. This query can return an arbitrary set of nodes, edges, and paths as well as some additional values. You see a small preview of the returned results as a graph drawing, where nodes are color-coded by their labels.
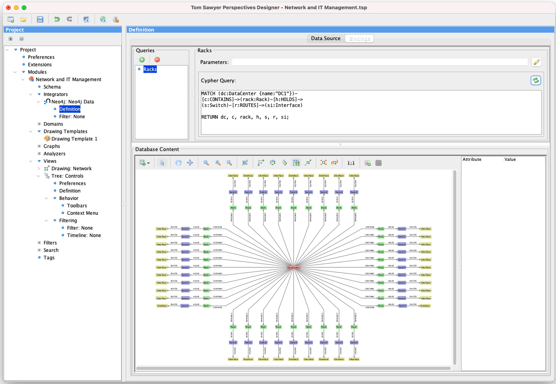
At this point, we have our data completely bound. You can deploy as-is, and the application will very happily generate models. No schema in sight.
Schemaless-ish
While using Dynamic Bindings to explore a database is where most developers start, it's not where they end up. Once they can see the data, they want to understand the structure. With the click of a button, you can switch to the schema mode. This compresses each node label onto a single node, revealing the topology of the data returned by the query.
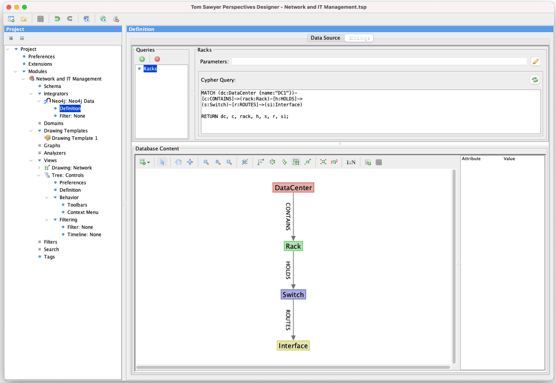
Now that you see the schema, you may find that having it is handy for other things. From this view, you can add all the node and edge types returned by this query to your project schema with another click.
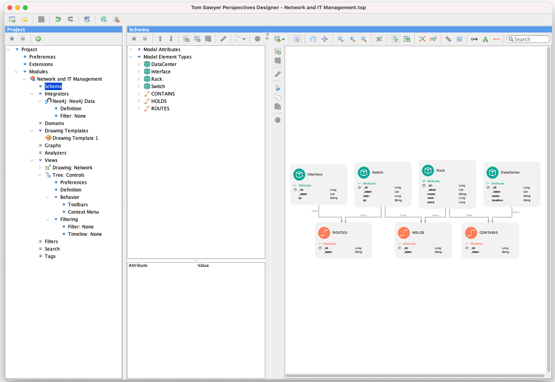
The integrator can also handle multiple queries, whose results may overlap with previously defined queries. Here we show another query returning shortest paths between a Rack and a Router, which adds the Egress::Router type. We can include it in our schema or just pick it up at runtime.
Making Everything Better
Dynamic Binding is one of those really special features that just makes everything better. It allows you to:
- Right-size your schema, importing only those portions that are useful to you and improving initial development
- View your data and validate that the query results are doing what you want with no prerequisites other than the database itself, improving debugging
- Eliminate duplicate round trips to the database, improving performance
- Eliminate copy-paste integrator configurations in your project files, improving maintainability
The notion of right-sized schemas extends from connecting to data all the way to displaying it. We call that a Domain; learn all about it in our next blog post. Meanwhile, if you haven't upgraded to Perspectives 10.0, get started now!
Existing users can simply check their e-mail and use the provided link to access our Download Products page. After signing in, follow the prompts to download the latest version. You can find additional information in the Upgrading section of the documentation.
New users can request a free trial. You’ll receive our software and complete product documentation.
About the Authors
Joshua Feingold is the Chief Technology Officer at Tom Sawyer Software. He's a Software Architect with experience providing solutions for customers across the spectrum of public and private, large and small, and technical and conceptual. He brings curiosity, an open mind, and a strong background in mathematics, engineering, software, and social and physical sciences to bear on the hardest problems facing modern organizations. He holds a Bachelor of Science in Mechanical Engineering from Caltech.
Austris Krastins is the Senior Technical Design Director at Tom Sawyer Software where he leads the architectural design of Tom Sawyer Software products. He works closely with Design Architects and Graphic Designers to ensure coherent user experience, extensible software components, and fast performing algorithms. He also helps the company to define streamlined engineering processes, standards, and best practices, working closely with the VP of Operations. He holds of Bachelor of Science in Computer Science from the University of Latvia.
Submit a Comment